用 Tesseract 开发一个你自己的文字识别应用
这次和大家聊聊文字识别相关的话题。 大家在平时肯定对各种扫描类的 APP 不陌生。 拿着手机摄像头对着任何文字,直接将摄像头中的文字内容转换成手机上可编辑的字符串。
文字识别,缩写叫做 OCR,全称 Optical character recognition,译为光学字符识别。 关于他的完整定义可以在 Wikipedia 上面找到:https://en.wikipedia.org/wiki/Optical_character_recognition。
完整的 OCR 算法,并不简单。 涉及到图像识别算法,以及将从图片中识别出来的文字转换成我们程序中可以使用的二进制形式。这其中还包括不同语言的字符如何识别,怎样更精准的识别等等。
设想一下,如果作为开发者,让你自己从头开发这样一套算法,恐怕要花掉很大力气。 不过好消息是,我们生活在这个开源时代,早已经有很多前辈们为我们趟好了道路。 这也是我们今天要聊的主题, Tesseract 就是这样一个开源库,给定任意一张图片,它可以识别出里面所有的文字内容,并且 API 接口使用非常简单。
Tesseract
Tesseract 是 Google 发布的一款 OCR 开源库,它支持多个变成语言环境,以及运行环境,其中包括我们这里将要介绍的 iOS 环境。 今天就用它带领大家开发一个属于你自己的 OCR 应用。
首先,需要安装 Tesseract, 最简单的方式是用过 Cocoapods, 进入你的项目根目录,输入:
pod init
然后,编辑生成的 Podfile 配置文件:
target 'ocrSamples' do
use_frameworks!
pod 'TesseractOCRiOS'
end
将TesseractOCRiOS加入配置列表中, 最后输入:
pod install
就完成了TesseractOCR IOS的安装。如果你之前没有接触过 Cocoapods 可以参看我们之前的文章http://swiftcafe.io/2015/02/10/swift-tips-cocoapods。
配置工作
安装完成后, 我们还需要进行一下简单的配置, 首先要在 Build Phases -> Link Binary With Libraries 中配置, 项目需要的依赖库, CoreImage, libstdc++, 以及 TesseractOCR IOS 自身:
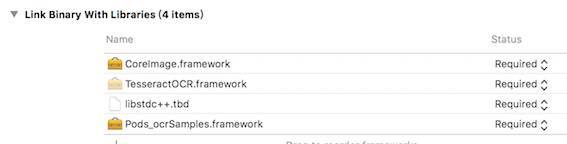
配置好依赖库之后, 我们还需要将文字识别训练数据添加进来, 训练数据是什么呢,TesseractOCR IOS识别图片的时候,会依照这个训练数据的规则来识别文字。比如中文,英文等,都有对应的训练数据,这可以理解为深度学习预先为我们训练好的模型。用它来进行核心的识别算法。
训练数据是需要按照不同语言来区分的,Tesseract 有专门的页面列出了所有可用的训练数据:https://github.com/tesseract-ocr/tesseract/wiki/Data-Files。
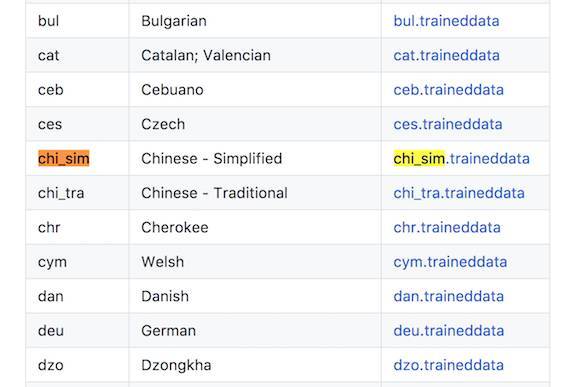
然后将训练数据拖放到工程中:
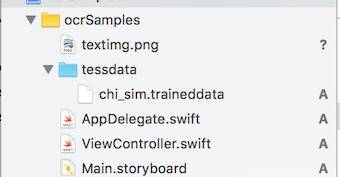
上图中的 chi_sim.traineddata 是我们下载的训练数据, 这里面有一点要注意的是, 这个文件必须要在 testdata 这个文件夹中。 并且这个文件夹要以 "Create Folder Reference" 的方式拖放进来:
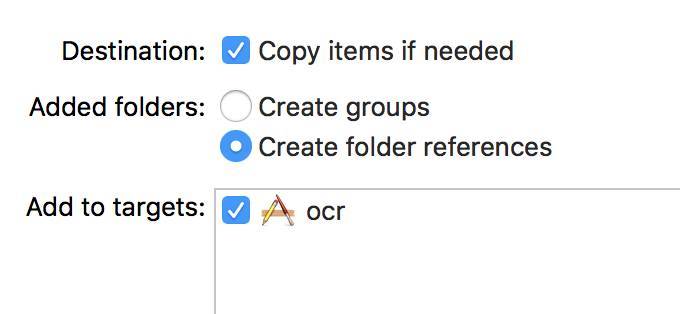
这种引用方式和另外一种 "Create Groups" 的方式有什么区别呢? 主要区别在于, 使用引用方式拖放进来的目录, 在最后生成 APP 包的时候, Main Bunlde 中是以 testdata/chi_sim.traineddata 这样的路径形式保存我们训练数据资源的, 如果使用 "Create Groups" 方式,最终存储的时候是会忽略文件夹名的,最后存储在 Main Bundle 中的文件是以 /chi_sim.traineddata 这个路径存放的。
而 TesseractOCRiOS, 默认情况下是会在 testdata/chi_sim.traineddata 这个路径查找训练数据的, 所以如果使用 "Create Groups" 方式拖入,会造成运行时找不到训练数据,而报错。 这点细节需要格外注意。
最后,为了让 TesseractOCRiOS 能够正确运行, 我们还需要关掉 BitCode, 否则会报编译错误,我们需要在两处都要关掉它,一个是至工程,另外一个是 Pods 模块, 如下图:
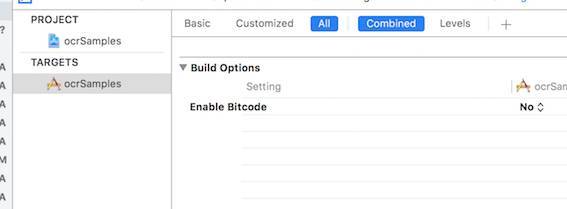
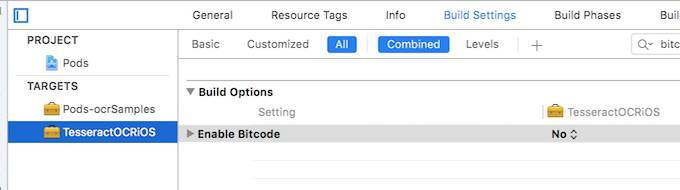
开始编码
做完上述的准备工作后, 我们就可以开始编码了, 这里只给大家展示最精简的代码。 首先我们需要在主界面上显示两个控件,一个是我们预先存储好的带有文字的照片, 另外一个是用于展示识别结果的文本框:
override func viewDidLoad() {
super.viewDidLoad()
self.imageView = UIImageView(frame: CGRect(x: 0, y: 80, width: self.view.frame.size.width, height: self.view.frame.size.width * 0.7))
self.imageView?.image = UIImage(named: "textimg")
self.view.addSubview( self.imageView!)
self.textView = UITextView(frame: CGRect(x: 0, y: labelResult.frame.origin.y + labelResult.frame.size.height + 20, width: self.view.frame.size.width, height: 200))
self.view.addSubview( self.textView!)
}
这里面我们只将两个控件的初始化关键代码写出来,其他不重要的代码都略去。 然后就可以调用 TesseractOCRiOS 来进行文字识别了:
func recognizeText(image: UIImage) {
iflettesseract= G8Tesseract(language: "chi_sim") {
tesseract.engineMode = .tesseractOnly
tesseract.pageSegmentationMode = .auto
tesseract.image = image
tesseract.recognize()
self.textView?. text= tesseract.recognizedText
}
}
所有识别相关的代码就都在这里了。首先调用 G8Tesseract 进行初始化, 我们传入训练数据的名称,这里是 "chi_sim" 代表简体中文。engineMode有三种可以选择的模式, tesseractOnly,tesseractCubeCombined 和 cubeOnly。 我们使用第一种模式,采用训练数据的方式。 cubeOnly 的意识就是使用更精准的 cube 方式, tesseractCubeCombined 就是两种模式的结合使用。
cube 模式需要额外的模型数据, 大致样例是这样:

上图是英文的 cube 识别模型。 简体中文的模型我暂时没有找到,所以我们这个实例中只是用到了 tesseractOnly 模式。 并且在没有 cube 模型数据的情况下,我们是不用使用tesseractCubeCombined 和 cubeOnly 的,否则会因为模型数据不存在而报错。 大家如果能够找到中文的 cube 模型,也欢迎在留言中反馈,这样会让这个文字识别更加精准。
其他的调用就不需要多讲了, 将要识别的 image 对象设置给 Tesseract。 然后调用它的 recognize 方法进行识别, 最后将识别结果 tesseract.recognizedText 设置给 TextView。
最终的运行效果如下:

上面的图片是我拍的 SwiftCafe 网站上一篇文章的照片, 从识别结果上看,还算比较准确。
总结
大家从上面的代码中应该也感受到了, Tesseract 虽然提供了本质上算是比较复杂的文字识别算法, 但它提供给开发者的接口可以说得上是非常简单。 OCR 文字识别从整体上来说,也可以算得上是 AI 的一个应用分支,在这个 AI 大行其道的时代,即便掌握一些应用技术,对我们开发者来说也可以很大的拓宽我们的视野。 发挥你的创意,也许类似 Tesseract 这些组件能够帮助你创造 AI 时代的新锐应用。
当然, Tesseract 目前自身还有一些缺陷,比如它只能识别印刷字体,而不能精准的识别手写字体。 不过那又怎么样呢,本来相当复杂的 OCR 算法,可以让我们用非常少的代价应用起来,还是一件对开发者非常幸福的事情。
照例,本文中的示例工程代码已经放到 Github 中,大家有需要可以直接下载:https://github.com/swiftcafex/Samples/tree/master/ocrSamples。
本文由 创作,采用 知识共享署名4.0 国际许可协议进行许可。本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名。最后编辑时间为: 2021/01/14 02:29