Tesseract-OCR 入门
Tesseract-OCR -01-Tesseract 介绍
OCR(Optical Character Recognition):
- 光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程
- Tesseract - OCR 引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封
- 数年以后,HP 意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生
- 在2005年,Tesseract 由美国内华达州信息技术研究所获得,并求诸于 Google 对 Tesseract 进行改进、消除Bug、优化工作,Tesseract 由惠普公司宣布开源
- 从2006年到现在,都由 Google 公司开发维护
Tesseract - OCR 特性
- 目前,Tesseract可以识别超过100种语言。也可以用来训练其它的语言
- 源码包提供了一个OCR的引擎——libtesseract 以及一个命令行程序——tesseract.exe
- Tesseract 支持多种输出格式,如:普通文本、html、pdf 等
对于开发者
- 开发者可以使用libtesseract的C/C++接口来构建自己的程序
- Tesseract从源码生成的文档可以在tesseract-ocr.github.io中找到
Windows下 Tesseract-OCR 的安装
- Tesseract-OCR Windows安装包下载:https://digi.bib.uni-mannheim.de/tesseract/
- 上面链接看着头疼就下我的网盘里的:
- 注意:安装的最后的时候,会有个最下面的项没有选中,选中它
- 安装的话就默认安装就好,如果选中那个在线安装包,会很慢,耐心等下
- 路径记住,配置环境要用
Windows下 Tesseract-OCR 的环境变量配置
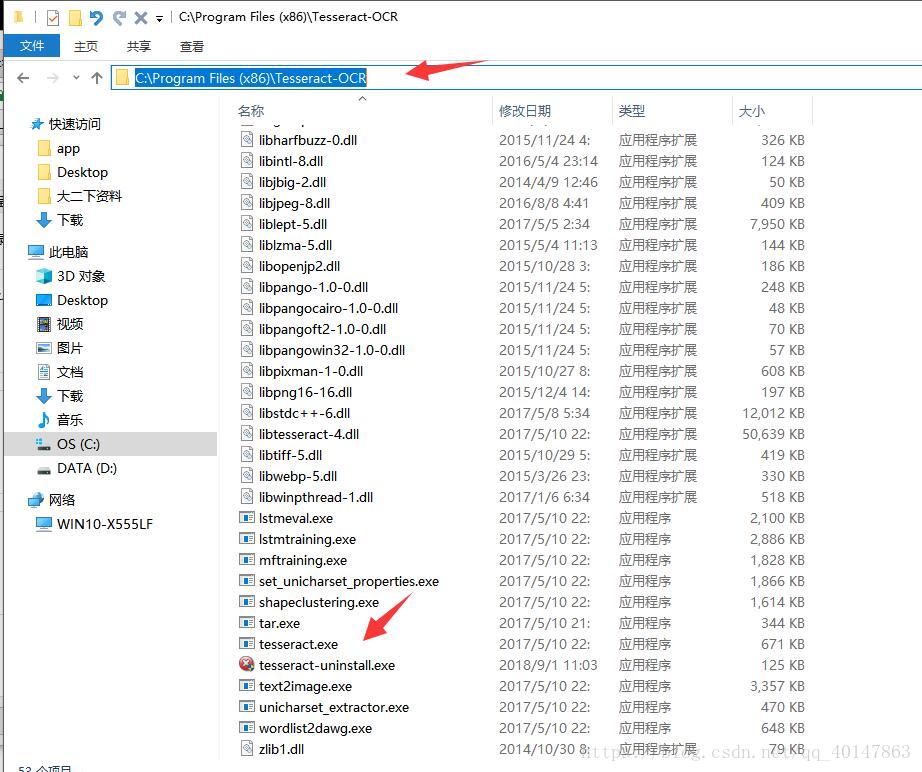
- 1.打开 Tesseract-OCR 的安装目录,拷贝路径
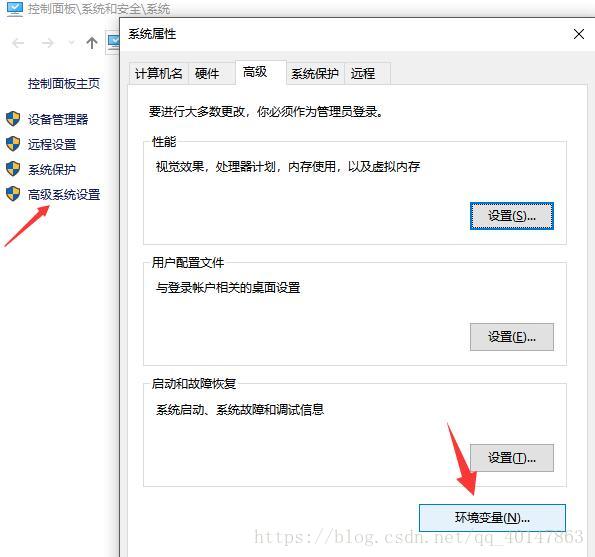
- 2.在【此电脑】右键,点击【属性】,找到【环境变量】
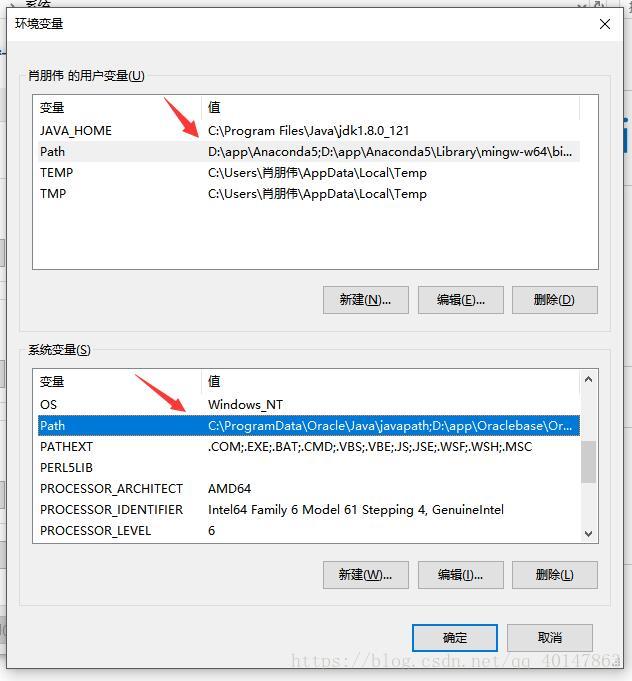
- 3.找到用户变量和系统变量 两个【Path】项点开,都添加刚才拷贝的Tesseract 的安装路径
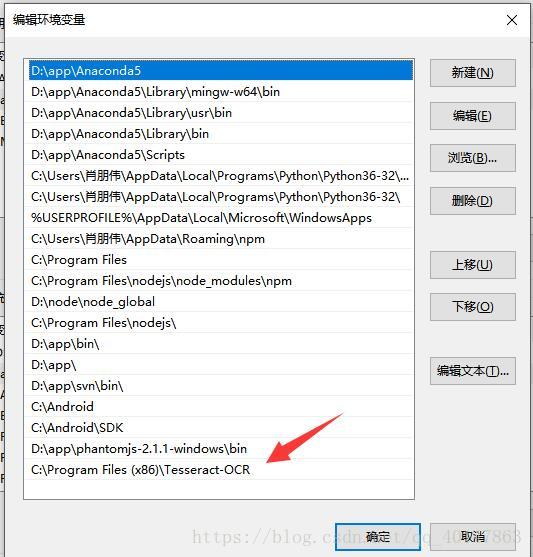
- 4.再找到【系统变量】,新建一个变量名称为:TESSDATA_PREFIX
值为:刚才路径加上 \tessdata
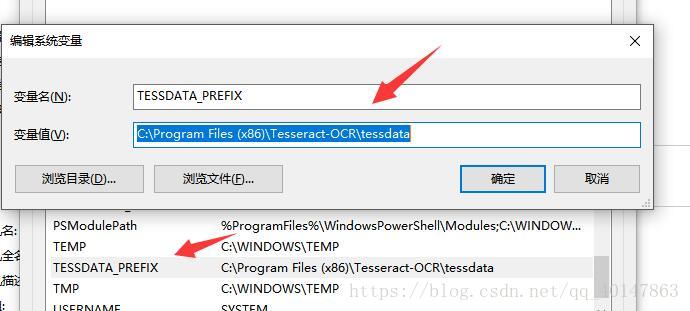
Tesseract 环境终于配置完成,去测试咯!
Tesseract-OCR 的文字识别测试
- 找一个需要识别的图片,比如这个test.jpg https://xpwi.github.io/Photos/p/test.jpg。放在一个好找的目录,最好是 D:\photos 这样的
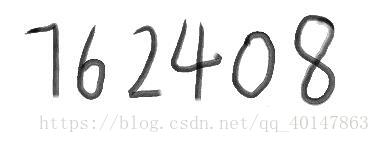
- 打开 cmd 进入该图片的文件夹
- 使用 cd 目录名 进入目录
- 使用 cd.. 返回上一级目录
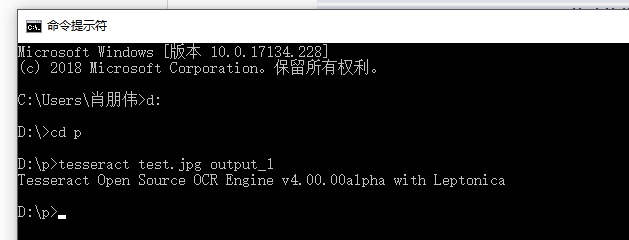
- 敲入: tesseract test.jpg output_1
- 操作截图:
运行结果:
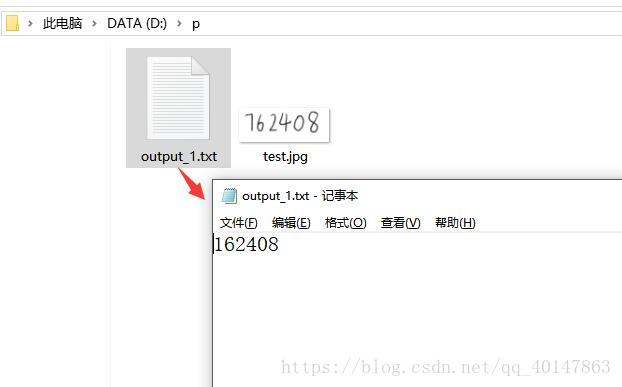 这里图片中的数字,有一个是识别错误的,就需要使用更多的数字去训练,才可以得到更高的准确率,关于训练数据,后面再介绍,关注我哦!
这里图片中的数字,有一个是识别错误的,就需要使用更多的数字去训练,才可以得到更高的准确率,关于训练数据,后面再介绍,关注我哦!
Tesseract-OCR 图片文字识别
使用 Tesseract-OCR 做图片文字识别,识别手写文字的时候,正确率能达到 90%,当训练后正确率是极高的。这里介绍的图片文字识别,可以识别英文,数字和中文等 。
-
**Tesseract:**一款由HP实验室开发由Google维护的开源OCR,我们可以不断的训练的库,使图像转换文本的能力不断增强;如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎
-
我搜集了几个素材,懒得找可以直接下载:
-
这里我是将图片放在了:D:\p
-
我们需要在 cmd 进入此目录
- 使用 cd 目录名 进入目录
- 使用 cd.. 返回上一级目录
-
使用 Tesseract 命令: tesseract 文件名 保存的txt文件名 -l eng 例:
tesseract num1.jpg num1
- 这里 -l eng 是设置语言,不写的话,默认是 eng 也就是英语
- 结果:
- 注意:
- 1.这里如果报错 Tesseract 不是内部或外部命令,就是环境变量没有配置好参照: https://blog.csdn.net/qq_40147863/article/details/82285920
- 2.如果识别的图片文字是中文会提示,0个文字
识别手写英文
- 识别图片 eng2.jpg

- 输入命令:保存为 eng2.txt

- 我们对比一下结果:
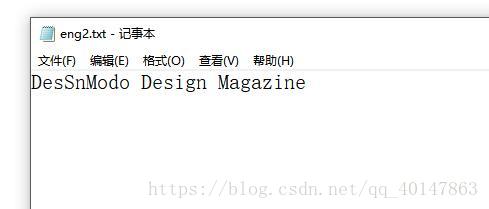
- 这里是识别错了一个字母,把 ig 错误的识别成 S,包括上面那张 数字也是错了一个
- 那也就是我们要努力的方向了
识别中文
- 这里识别中文只需要将 -l 参数改成 chi_sim 例如:
- 对 有中文文字的图片 chi1.jpg ,进入图片路径,使用一下命令:
**tesseract chi1.jpg chi1 -l chi_sim **
- 图片样式:

- 执行命令:
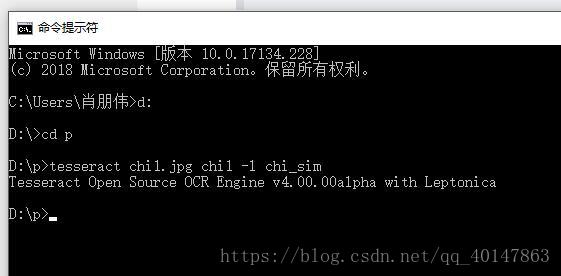
- 运行结果:
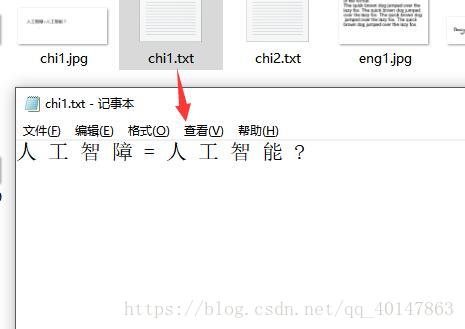
识别英文和数字夹杂验证码
- 例如:
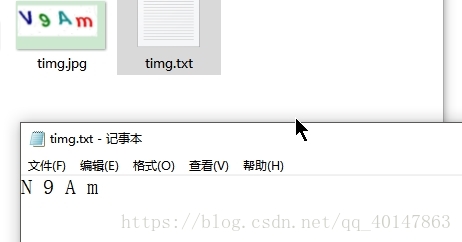
- 对 图片 timg.jpg ,进入图片路径,使用一下命令:
tesseract timg.jpg timg
- 图片样式:
- 执行命令:
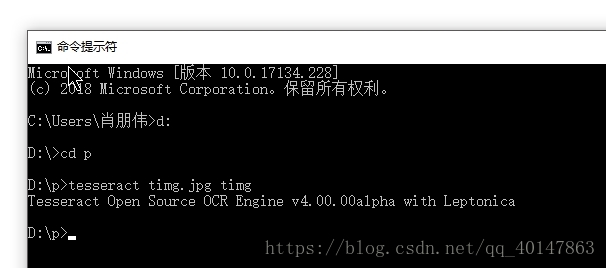
- 运行结果:
Tesseract 训练:
- 我们可以通过重复的训练,用更多的数据去训练,就可以达到更多高的识别正确率
- 我们使用 jTessBoxEditor 训练
- 由于 jTessBoxEditor 的安装和训练,内容比较多,我再整理一篇
Tesseract-OCR-04-使用 jTessBoxEditor 进行训练
- 本篇是关于 jTessBoxEditor 进行训练,使 Tesseract-OCR 文字识别准确率得到极大的提高,本篇完善了很多细节,初学者也可以看懂,一起学习吧!
- 想要一遍成功要细心关注【注意】,我踩过的坑都标出来了
训练的大致步骤:
- 1.安装 jTessBoxEditor
- 2.获取样本文件
- 3.Merge 样本文件
- 4.生成 .box 文件
- 5.定义字符配置文件
- 6.字符矫正
- 7.执行批处理文件
- 8.将生成的 num.trainddata 放入 Tesseract 安装目录的 tessdata 文件夹里
1.安装 jTessBoxEditor
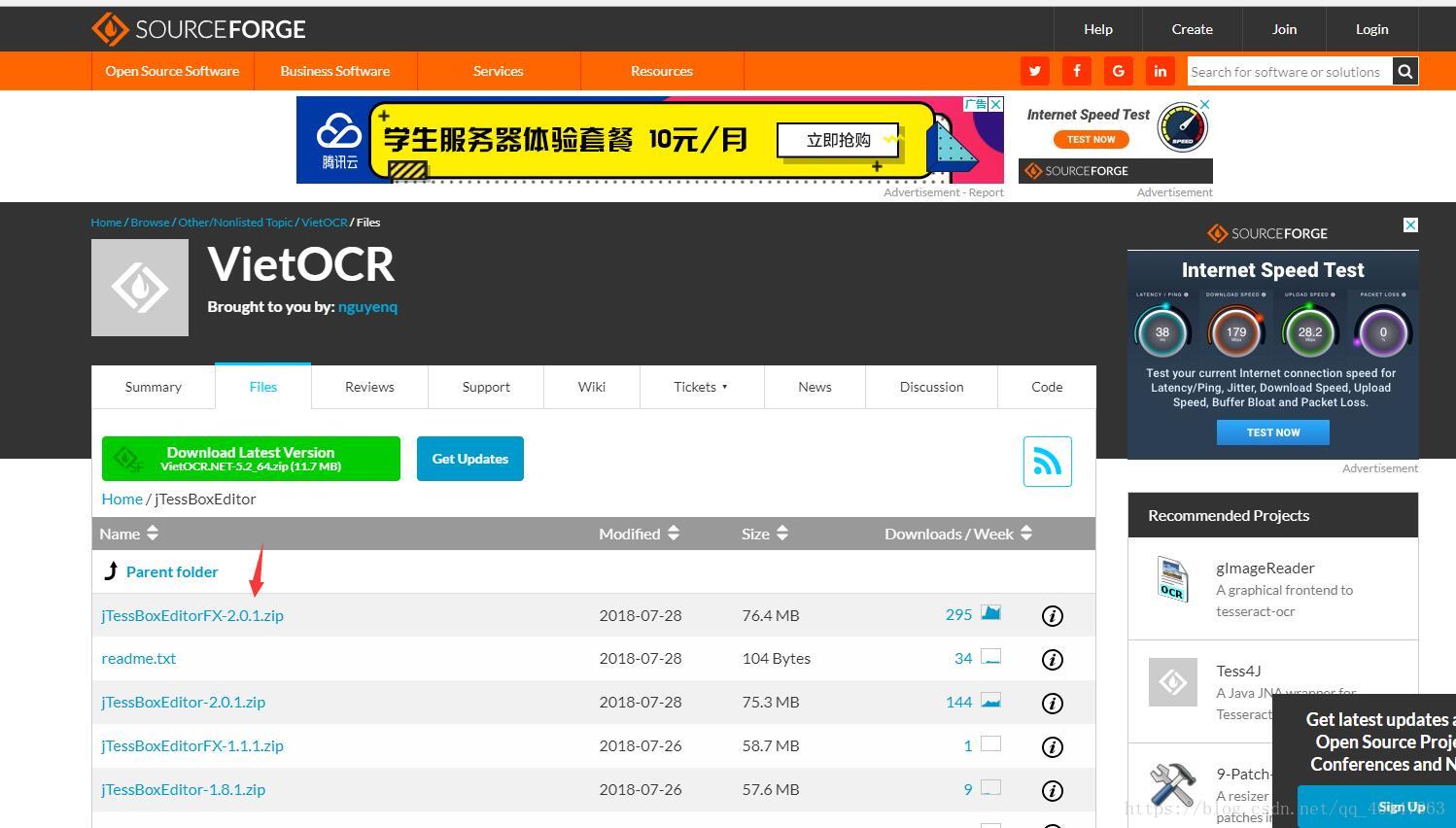
- 下载jTessBoxEditor,地址https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
- 解压后得到jTessBoxEditor
- 由于这是由Java开发的,所以我们应该确保在运行jTessBoxEditor前先安装JRE(Java Runtime Environment,Java运行环境)
- 没有安装 jre 的可以到官网下载安装:
http://www.oracle.com/technetwork/java/javase/downloads/jre8-downloads-2133155.html
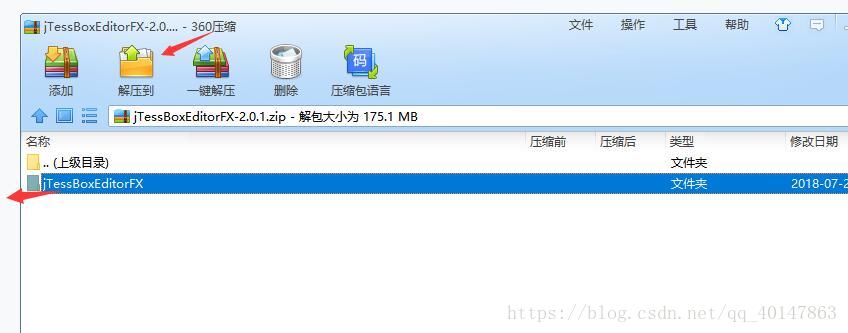
- jre 安装就不仔细介绍了,因为能找到这篇的,基本都安装过了,下面介绍 jTessBoxEditor
- 但是呢,这个 jTessBoxEditor ,不用安装,直接解压就可以,单击解压到或者直接拉出来就可以了
2.获取样本文件
- 我们可以用画图工具绘制样本文件,数量越多越好,我自己画了 5 张图作为训练的数据,如图:
- **【注意】:样本图像文件格式必须为tif\tiff格式,**否则在Merge样本文件的过程中会出现 Couldn’t Seek 的错误。
- 再转格式嫌麻烦就直接拿走我的:https://pan.baidu.com/s/1hoTkxMVw5z_ve9hzftLOqw





3.Merge样本文件
- 在安装目录找到一个【train.bat】打开 jTessBoxEditor >【Tools】>【Merge TIFF】
- 操作截图:
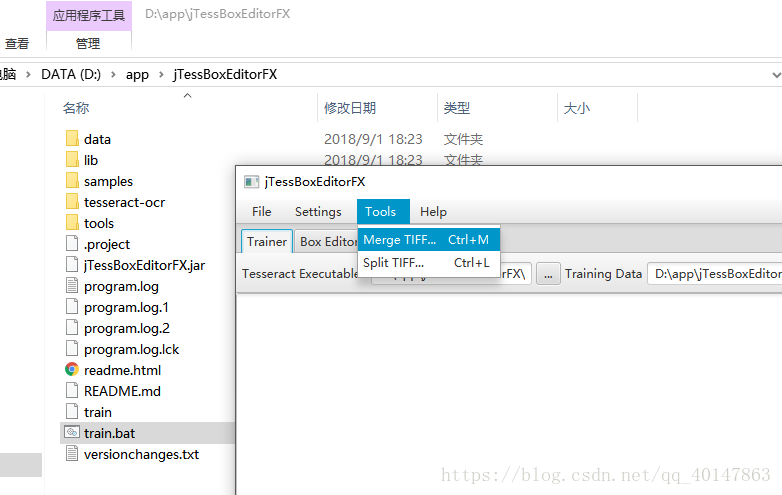
- 将样本文件全部选上,安装 Ctrl 键不松
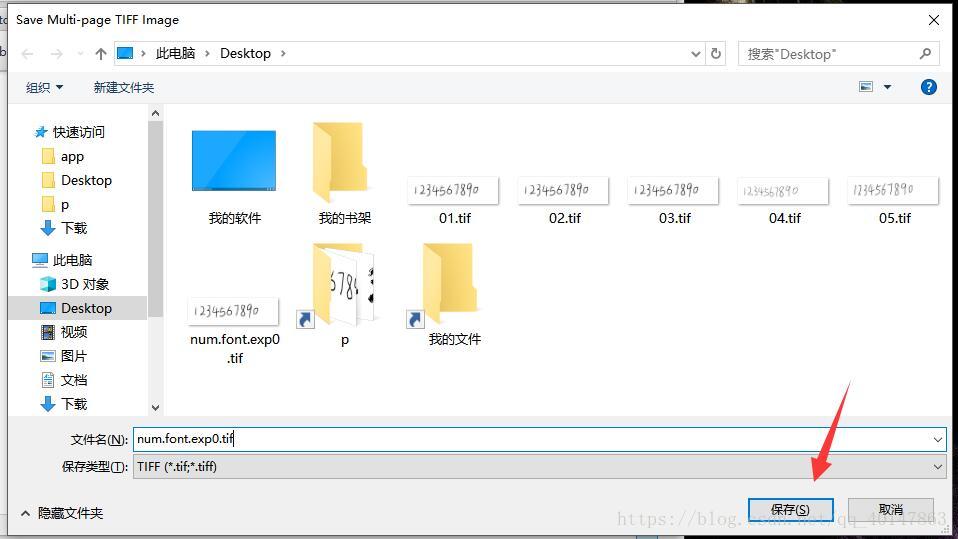
- 【注意】:这里是没有界面化的提示的,选中后,点击【打开】,立马就是输入合成后的文件名界面,输入num.font.exp0.tif,点击【保存】
- 也就是将合并文件保存为 num.font.exp0.tif
4.生成BOX文件
- 打开 cmd 并切换至 num.font.exp0.tif 所在目录
- 使用 cd 目录名 进入目录
- 使用 cd.. 返回上一级目录
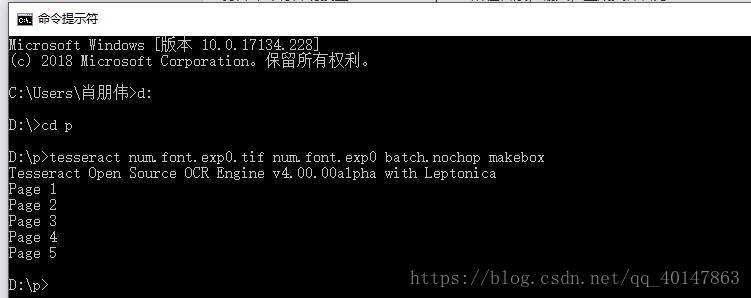
- 输入下面命令,生成文件名为num.font.exp0.box
tesseract num.font.exp0.tif num.font.exp0 batch.nochop makebox
【语法】:tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
【语法】:lang为语言名称,fontname为字体名称,num为序号;在tesseract中,一定要注意格式
- 操作截图
 如果报错可能是没有进入合并好的 tif 文件目录下,也可能是没有换成自己用的文件名哦
如果报错可能是没有进入合并好的 tif 文件目录下,也可能是没有换成自己用的文件名哦
5.定义字符配置文件
- 在文件夹文件夹内,新建一个文本文件,名为font_properties,删掉.txt,用记事本打开,写入内容为:
font 0 0 0 0 0
【语法】:<fontname> <italic> <bold> <fixed> <serif> <fraktur>
【语法】:fontname为字体名称,italic为斜体,bold为黑体字,
fixed为默认字体,serif为衬线字体,fraktur德文黑字体,
1和0代表有和无,精细区分时可使用
6.准备环节
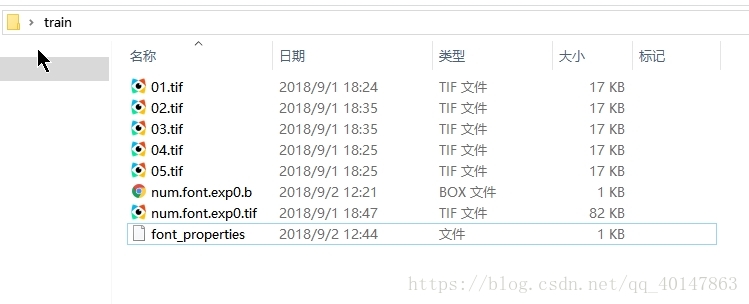
- 将5个tif文件,num.font.exp0.tif,生成的num.font.exp0.box文件,还有font_properties文件放在同一个目录下
- 目前8个文件,截图:
7.字符矫正
- 打开 jTessBoxEditor>【BOX Editor】> 【Open】,打开num.font.exp0.tif;矫正【Char】上的字符
- 操作截图:
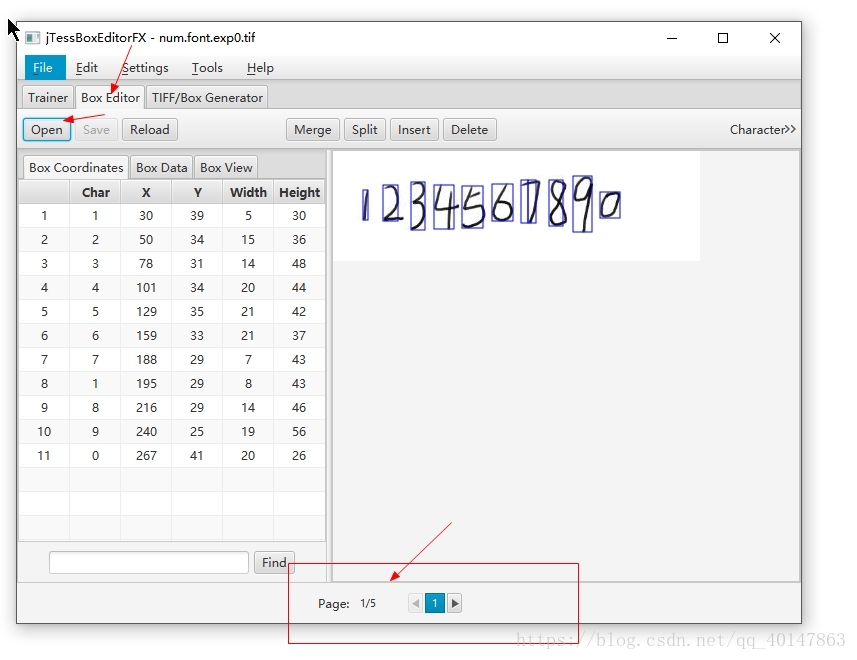
- 【注意】:记得[Page]有好多页哦!修改后记得保存
- 当然有可能生成的 box 文件后,会多一个盒子,它把7识别成了两个
- 处理方式:自己根据看到的数字修改char,如果不是完整字符就敲 空格,然后回车
- 操作截图:
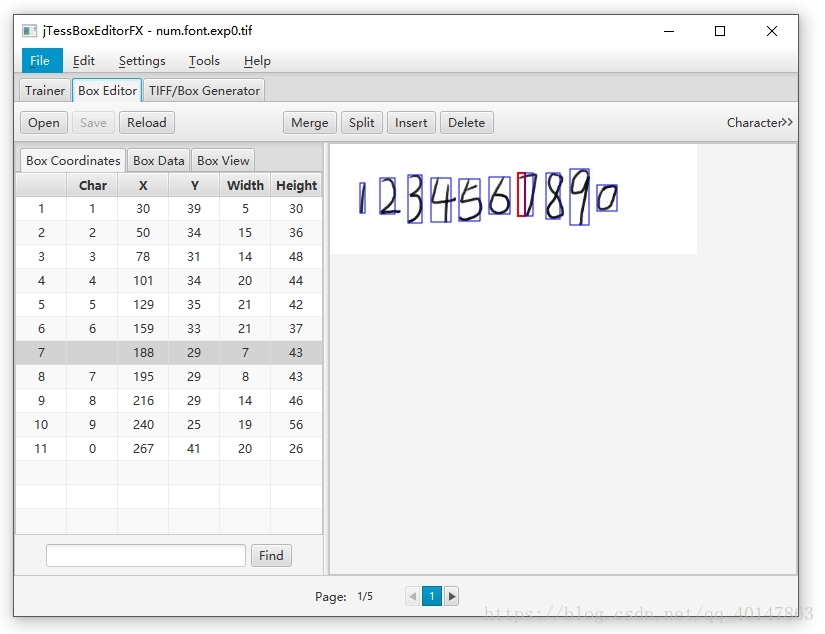
- 然后就是依次处理 5 页
- 最后保存,替换原来的 box 文件
8.执行批处理文件
- 【注意】:执行该批处理文件前,先要目录下创建font_properties文件 ,也就是滴 5 步
- **在目标目录下,新建一个txt文件,复制代码,重命名为 do.bat,直接更改后缀名就可以 **
- 代码如下
echo Run Tesseract for Training..
tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
echo Compute the Character Set..
unicharset_extractor.exe num.font.exp0.box
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
echo Clustering..
cntraining.exe num.font.exp0.tr
echo Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable
echo Create Tessdata..
combine_tessdata.exe num.
echo. & pause
- 保存后,双击执行即可,执行后会在文件夹生成很多文件,如下:
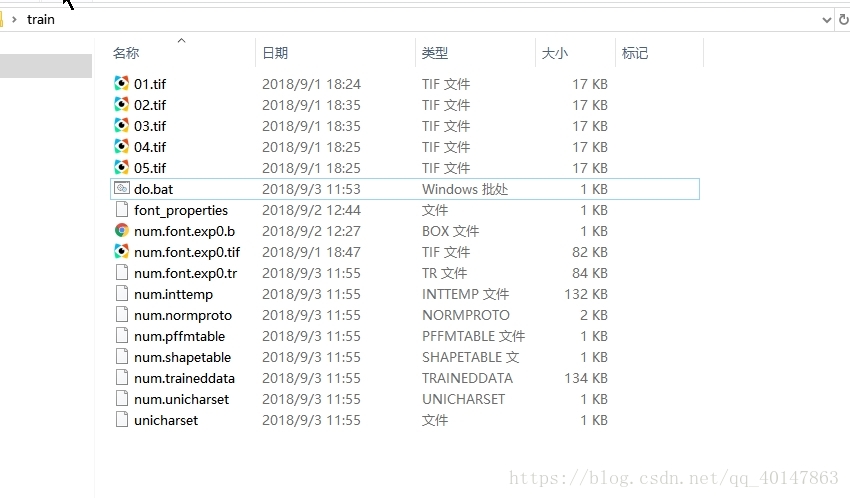
9.拷贝 num.trainddata 文件
- 最后将 num.trainddata 复制到 Tesseract-OCR 安装目录下的 tessdata 文件夹
- 【注意】:这里是【Tesseract-OCR 安装目录下的 tessdata 文件夹】
10.大功告成,测试结果
- 这里我是将图片 num1.jpg 放在了:D:\p
- 我们需要在 cmd 进入此目录
- 使用 cd 目录名 进入目录
- 使用 cd.. 返回上一级目录
- 使用 Tesseract 命令:
- 【注意】:语言参数要设置成 num,就是我们刚才拷贝的,没拷贝 num.trainddata 文件不能使用 tesseract 文件名 保存的txt文件名 例:
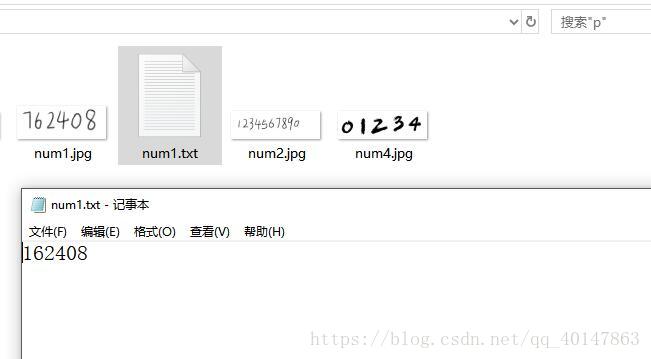
tesseract num1.jpg num01 -l num
- 操作截图:
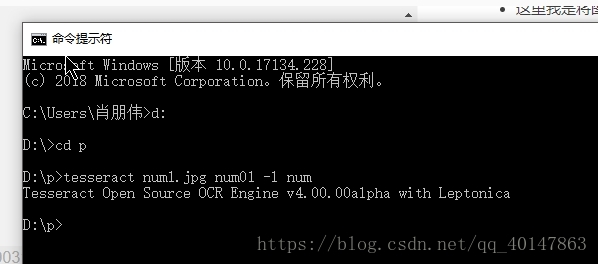
- 运行结果:
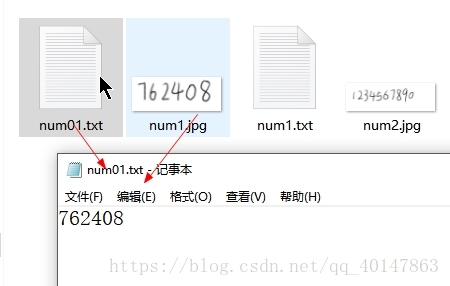
- 我们可以看到新生成的文件 num01 的内容为 762408,内容完全正确。细心的人会发现,最后一句指令,我们使用了指令[-l num]而不是[-l eng]。这说明,最后一次转换我们使用的是新生成的num语言的匹配库而不是默认的 eng 语言匹配库
- 我们可以看到,经过简单的训练,我们对于数字数据的转换准确率提高了很多
Tesseract-05-主要API功能介绍
- tesseract本身代码是由c/c++混编而成的,其中有用的简单的接口函数几乎都是在baseapi.h中
- 从其处理过程中,不难得出:
- 它还需要有一个image处理的类,及相关的方法;
- 这样子,读取图片后,生成image对象,再获取相关的参数;
- 当然还需要有对image对象的读取,版面分析等接口函数;
- 再次,它还定义了很多自身的数据类型,比如:BITS16、array_record、BLOCK、IMAGE等;
- 而且它具有自学的能力
现在,我们从头有调理地简单讲述一下子:
- tesseract::TessBaseAPI,基础的接口函数,包含了初始化,简单的 处理图片文字信息,版面分析的结果体等。
- IMAGE,只是一个类,里边封装了相关的图片操作,包括图片的 读取,图片参数信息的获取等。
- 其他,包括数据类型声明,相关结构体声明,跨平台处理,命令端参数提取等。 我们在实际中用到的就是前两个里边的东西
声明:以下函数皆是在 tesseract::TessBaseAPI 域下
1: SetImage
函数声明:
void tesseract::TessBaseAPI::SetImage ( const unsigned char * imagedata,
int width,
int height,
int bytes_per_pixel,
int bytes_per_line
)
为Tesseract 提供待识别的图片。
2:SetSourceResolution
函数声明:
void tesseract::TessBaseAPI::SetSourceResolution(int ppi)
设置源图像的分辨率(像素每英尺),可以计算最终的字体大小信息。 SetImage之后调用此函数。
3:SetRectangle
函数声明:
void tesseract::TessBaseAPI::SetRectangle ( int left,
int top,
int width,
int height
)
将识别限制到图像的一个子矩形区域,SetImage 之后调用此函数。每一次该函数调用后将清除识别结果,以便同一张图像可以进行多矩形区域的识别。
4:SetThresholder
函数声明:
void tesseract::TessBaseAPI::SetThresholder(ImageThresholder * thresholder)
在一些特殊的情况下, 通常是产生一个阈值器类的子类的时候,该函数可以提供一个不同的阈值器,阈值器可能会随着图片和设定预装入,或者被随后设定。Tesseract 拥有阈值器支配权,并在它被替换或是API被析构后删除。
5:GetThresholdedImage
函数声明:
Pix * tesseract::TessBaseAPI::GetThresholdedImage()
从Tesseract获得内部阈值图像的拷贝,在SetImage 或者TesseractRect 之后可以随时别调用。 注意,只有安装了Leptonica之后才可使用。
6:GetRegions
函数声明:
Boxa * tesseract::TessBaseAPI::GetRegions ( Pixa ** pixa )
以aleptonica-style Boxa, Pixa pair 格式获得页面结构分析的结果,在Recognize前后均可被调用。
7:GetTextlines
函数声明:
Boxa * tesseract::TessBaseAPI::GetTextlines ( Pixa ** pixa,
int ** blockids
)
以aleptonica-style Boxa, Pixa pair 格式获取文本行,在Recognize前后均可被调用。如果blockids(block数目) 是空的话,每行block- id返回每行一个元素的数组,使用之后被删除。
8:GetStrips
函数声明:
Boxa * tesseract::TessBaseAPI::GetStrips ( Pixa ** pixa,
int ** blockids
)
以aleptonica-style Boxa, Pixa pair 格式获取图像区域的文本行和条形区域,方便后面非矩形区域的处理。在Recognize前后均可被调用
9:GetWords
函数声明:
Boxa * tesseract::TessBaseAPI::GetWords(Pixa ** pixa)
以aleptonica-style Boxa, Pixa pair 格式获取图像区域的文字,在Recognize前后均可被调用。
10:GetConnectedComponents
函数声明:
Boxa * tesseract::TessBaseAPI::GetConnectedComponents ( Pixa ** pixa )
在页面分析之后识别之间,以aleptonica-style Boxa, Pixa pair 格式获得独立连通的文本区域,在Recognize前后均可被调用。
11:GetComponentImages
函数声明:
Boxa * tesseract::TessBaseAPI::GetComponentImages ( PageIteratorLevel
level,
bool text_only,
Pixa ** pixa,
int ** blockids
)
以aleptonica-style Boxa, Pixa pair 格式获得制定级别的元素(block,textline, word),在Recognize前后均可被调用。果blockids(block数目) 是空的话,每行block- id返回每行一个元素的数组,使用之后被删除。如果text_only 为真, 只有text可被返回。
12:GetThresholdedImageScaleFactor
函数声明:
int tesseract::TessBaseAPI::GetThresholdedImageScaleFactor()const
返回阈值图像的比例系数,该阈值图像由yGetThresholdedImage() 和调用了GetComponentImages()的GetX()函数返回。
13:DumpPGM
函数声明:
void tesseract::TessBaseAPI::DumpPGM ( const char * filename )
将内部二值图像放到PGM文件中。
14:AnalyseLayout
函数声明:
PageIterator * tesseract::TessBaseAPI::AnalyseLayout()
以SetPageSegMode设定的模式进行页面结构分析,返回一个(iterator),错误返回为空。Iterator 使用后必须删除。注意:该函数指向TessBaseAPI 类内部的数据,因此必须在TessBaseAPI 存在的情况下才可被调用。不能被改变内部PAGE_RES的 Init, SetImage, Recognize, Clear, End DetectOS或者其他调用。
15:Recognize
函数声明:
int tesseract::TessBaseAPI::Recognize(ETEXT_DESC * monitor)
识别 来自SetAndThresholdImage的图像, 产生Tesseract 内部结构数据,成功返回0,如果需要,下面的Get*Tex函数会调用它。识别完成后,在SetImage之前,输出都会保持在内部。
16:RecognizeForChopTest
函数声明:
int tesseract::TessBaseAPI::RecognizeForChopTest(ETEXT_DESC * monitor)
检索来自SetAndThresholdImage(), Recognize() or TesseractRect()的信息(在需要的情况下隐式调用Recognize)。对Recognize 变化一测试chopper.
17:ProcessPages
函数声明:
bool tesseract::TessBaseAPI::ProcessPages ( const char * filename,
const char * retry_config,
int timeout_millisec,
STRING *
text_out
)
识别指定文件的所有页面,文件格式为(a multi-page tiff or list of filenames, or single image), 并且根据参数(tessedit_create_boxfile, tessedit_make_boxes_from_boxes, tessedit_write_unlv, tessedit_create_hocr.)得到合适的文本。在输入文件的每一页运行ProcessPage,输入文件可以是(a multi-page tiff, single-page other file format, or a plain text list of images to read),返回值放在text_out中。如果tessedit_page_number 非负,程序将会在其所代表那一页开始。运行错误返回false. 如果程序暂停在某一页timeout_millisec (非负) 时间终止程序,或者由于某些原因一些页面处理失败,该页面将会以retry_config 的配置文件重新处理。
18:ProcessPage
函数声明:
bool tesseract::TessBaseAPI::ProcessPage ( Pix * pix,
int page_index,
const char * filename,
const char * retry_config,
int timeout_millisec,
STRING *
text_out
)
为 ProcessPages进行单页面识别。Text放到text_out中, pix是文件名,page_index是边缘处理后的元数据,比如box文件,或者hOCR格式文件。
19:GetIterator
函数声明:
ResultIterator * tesseract::TessBaseAPI::GetIterator()
为 LayoutAnalysis and/or Recognize运行结果获取读取顺序的迭代器(iterator),使用之后删除。
20:GetMutableIterator
函数声明:
MutableIterator * tesseract::TessBaseAPI::GetMutableIterator()
为 LayoutAnalysis and/or Recognize运行结果获取可变的迭代器(iterator),使用之后删除。
21:GetUTF8Text
函数声明:
char * tesseract::TessBaseAPI::GetUTF8Text()
识别的文本被返回为字符指针,以UTF8编码(must be freed with the delete [] operator)。从内部数据结构中获得文本字符串。
本文由 创作,采用 知识共享署名4.0 国际许可协议进行许可。本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名。最后编辑时间为: 2021/01/14 03:57