kubernetes常见错误问题及解决办法
问题一
Warning FailedScheduling 54s default-scheduler 0/1 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate
使用kubeadm初始化的集群,出于安全考虑Pod不会被调度到Master Node上,不参与工作负载。允许master节点部署pod即可解决问题,命令如下:
kubectl taint nodes --all node-role.kubernetes.io/master-
补充点(禁止master部署pod命令):
kubectl taint nodes k8s node-role.kubernetes.io/master=true:NoSchedule
问题二:节点初始化报错
[ERROR FileContent–proc-sys-net-ipv4-ip_forward]: /proc/sys/net/ipv4/ip_forward contents are not set to 1
使用命令如下解决:
echo 1 > /proc/sys/net/ipv4/ip_forward
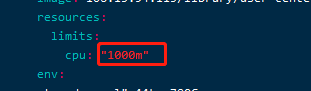
问题三:节点资源不足导致的问题
FailedScheduling 55s (x4 over 3m28s) default-scheduler 0/3 nodes are available: 3 Insufficient cpu
节点4c8g规格,创建副本两个且资源限制2000m时候出现问题,修改成1000m或修改副本等方式小时4000m即可解决
问题四:kubectl get 报错:kubectl Unable to connect to the server: dial tcp 10.12.2.199:6443: i/o timeout
具体输出如下:
场景:高可用集群 master 节点,当我执行:kubectl get nodes,出现如下错误:
kubectl Unable to connect to the server: dial tcp 10.12.2.199:6443: i/o timeout
原因是 Master 节点初始化集群的时候,没有执行:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
执行完毕即可。
问题五:Unable to connect to the server: x509: certificate signed by unknown authority
问题复现
昨天按照教程搭建了一个集群,今天想重新实验下,于是执行kubeadm reset命令清除集群所有的配置。
接着按照部署的常规流程执行kubeadm init --kubernetes-version=v1.14.3 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=0.0.0.0命令创建集群。然后执行以下几个命令:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
接着当我执行kubectl get nodes等命令时,所有的命令都会打印出错误:Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of “crypto/rsa: verification error” while trying to verify candidate authority certificate “kubernetes”)
当在这些 kubectl 命令后加入 --insecure-skip-tls-verify 参数时,就会报如下错误:error: You must be logged in to the server (Unauthorized)
问题解决过程
期间,我尝试了所有能搜索的相关资料,都没有一个好使的。我还确认了kubeadm reset命令会完全清除已创建的集群配置,那么为什么清配置后重新创建集群却不行呢?实在没办法我把注意力集中到额外执行的这几个命令上:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
这几个命令会创建一个目录,并复制几个配置文件,重新创建集群时,这个目录还是存在的,于是我尝试在执行这几个命令前先执行rm -rf $HOME/.kube命令删除这个目录,最后终于解决了这个问题!!!
总结
这个问题很坑人,删除集群然后重新创建也算是一个常规的操作,如果你在执行 kubeadm reset命令后没有删除创建的 $HOME/.kube目录,重新创建集群就会出现这个问题!
本文由 创作,采用 知识共享署名4.0 国际许可协议进行许可。本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名。最后编辑时间为: 2021/02/13 05:17