iOS开发基于OpenCV处理实现身份证号码识别
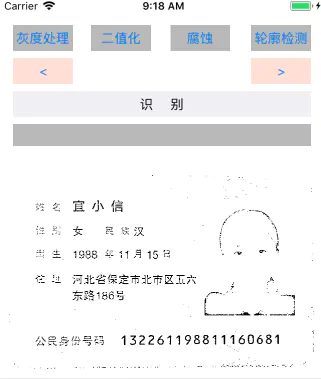
实现效果展示
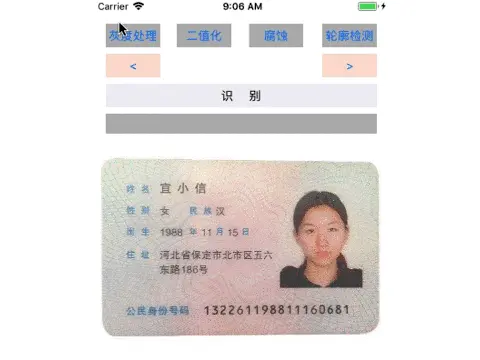
技术要点分析:此次项目中主要的技术划分为身份证号码区域提取和光学字符识别。
- 身份证号码区域的提取涉及有:
- 图像灰度化
- 阀值二值化
- 腐蚀
- 轮廓检测,获取身份证号码区域 这里的处理则需要使用到OpenCV开源库。
- 光学字符识别主要集成TesseractOCRiOS框架。
OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉库,可以运行在Linux、Windows、Android,iOS和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法,开发中一般用来做图片视频的处理,图形识别,机器学习等应用。 OpenCV目前分为两个版本:OpenCV2.4.x和OpenCV3.x,并且这两个版本都在持续更新中(最新为3.3.1和2.4.13.4)。根据网上的资料,OpenCV3.x是一个阉割后的版本,OpenCV3.x把重要的nonfree模块去掉了。本例中集成的是3.x版本,至于强大的2.4.x版本也有对应的framework可供下载,如果有成功编译2.4.x版本的朋友也可分享一下相关教程!
一. OpenCV的环境搭建
最开始是准备直接使用CocoaPods集成,pod search 是 'OpenCV', '~> 3.2.0'版本,但是好像包挺大的,install几次都失败了,无奈才去官网下载framework自己手动集成编译了
-
首先下载最新的framework,进入链接等待几秒会自动跳转下载状态。点击进入
-
下载完成后,直接拖入已创建好的工程内。
-
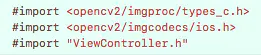
引用下面头文件:
-
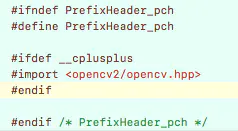
另外还有一个头文件#import <opencv2/opencv.hpp>也需要引入,这里采用PCH文件引入,之前尝试在.mm文件内引入但会报错。
-
导入完成,然后build,会报错:
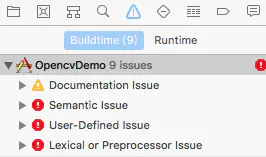
这是因为OpenCV是基于C++编写,如果要使用C++类或者特性就需要把该文件扩展名改为.mm。
.m & .mm:
.m :源代码文件。这是典型的源代码文件扩展名,可以包含Objective-C和C代码。
.mm :源代码文件。带有这种扩展名的源代码文件,除了可以包含Objective-C和C代码以外还可以包含C++代码。仅在你的Objective-C代码中确实需要使用C++类或者特性的时候才用这种扩展名
再build 就OK了。
二. 开始图像的第一步处理了 -- 图像灰度化:
将彩色图像转化成为灰度图像的过程称为图像的灰度化处理。 灰度化,在RGB模型中,如果R=G=B时,则彩色表示一种灰度颜色,其中R=G=B的值叫灰度值,因此,灰度图像每个像素只需一个字节存放灰度值(又称强度值、亮度值),灰度范围为0-255。 彩色图像中的每个像素的颜色有R、G、B三个分量决定,而每个分量有255中值可取,这样一个像素点可以有1600多万(255255255)的颜色的变化范围。而灰度图像是R、G、B三个分量相同的一种特殊的彩色图像,其一个像素点的变化范围为255种,所以在数字图像处理中一般先将各种格式的图像转变成灰度图像以使得后续图像的计算量变得少一些。灰度图像的描述与彩色图像一样仍然反映了整幅图像的整体和局部的色度和亮度等级的分布和特征。一般有四种方法对彩色图像进行灰度化处理:分量法、最大值法、平均值法、加权平均法。
这里直接调用函数:
void cvtColor(InputArray src, OutputArray dst, int code, int dstCn=0)
C++:void cvtColor(InputArray src, OutputArray dst, int code, int dstCn=0)
参数解释:
InputArray src –-输入图像即要进行颜色空间变换的原图像,可以是Mat类
OutputArray dst –-输出图像即进行颜色空间变换后存储图像,也可以Mat类
int code –-转换的代码或标识
int dstCn = 0 –-目标图像通道数,如果取值为0,则由src和code决定
灰度化处理处理后的效果为:
 灰度化之后请勿再次灰度化,会直接crash
灰度化之后请勿再次灰度化,会直接crash
三. 阀值二值化
把一幅多灰度值的图像(Gray Level Image)转化为只有黑(前景文字部分)白(背景部分)分布的二值图像(Binary Image)的工作叫做二值化处理(Binariztion)。对于一般256级灰度的灰度图,0级灰度对应于黑色,255级对应于白色。二值化后0对应于黑色前景文字,1对应于白色背景。二值化方法可以分为: 全局二值化 和 局部自适应二值化。
- 全局二值化方法(Global Binariztion Method)对每一幅图计算一个单一的阀值。灰度级大于阈值的像素被标记为背景色,否则为前景。
- 局部二值化方法(Local Adaptive Binarization Method)以像素的邻域的信息为基础来计算每一个像素的阈值。其中一些方法还会计算整个图像中的一个阈值面。如果图像中的一个像素(x,y)的灰度级高于在(x,y)点的阈值面的计算值,那么把像素(x,y)标记为背景,否则为前景字符。
- 全局固定阀值二值化:可直接使用固定函数完成
C++:double cvThreshold(constCvArr* src, CvArr* dst, double threshold, double max_value,int threshold_type)
参数说明:
- src –-原始数组 (单通道 , 8-bit of 32-bit 浮点数)
- dst –-输出数组,必须与 src 的类型一致,或者为 8-bit
- thresh –-阈值
- max_value -–使用 CV_THRESH_BINARY 和 CV_THRESH_BINARY_INV 的最大值
- threshold_type -–对图像取阈值的方法。threshold_type:本函数支持的对图像取阈值的方法由 threshold_type 确定,就是显示的轮廓会有不同。Types of thresholding :
define CV_THRESH_BINARY-- 0 --value = value > threshold ?max_value : 0
define CV_THRESH_BINARY_INV-- 1 -- value = value > threshold ? 0 : max_value
define CV_THRESH_TRUNC-- 2 --value = value > threshold ?threshold : value
define CV_THRESH_TOZERO-- 3 --value = value > threshold ? value : 0
define CV_THRESH_TOZERO_INV-- 4 --value = value > threshold ? 0 : value
define CV_THRESH_MASK 7
define CV_THRESH_OTSU-- 8 --use Otsu algorithm to choose the optimal threshold value
combine the flag with one of the above CV_THRESH_values
值得一说的是threshold_type可以使用CV_THRESH_OTSU类型,这样该函数就会使用大律法OTSU得到的全局自适应阈值来进行二值化图片,而参数中的threshold不再起作用 在这里需要注意src必须是单通道图像,如果直接操作彩色图会crash
关于图像通道:
一个图形的通道数是N,就表明每个像素点处有N个数,一个axb的N通道图像,图像矩阵实际上是b行Nxa列的数字矩阵。
OpenCV中图像的通道可以是1,2,3,4。
1. 通道的是灰度图RGB555和RGB565。
2. 通道的图像是RGB555和RGB565。2通道图在程序处理中会用到,如傅里叶变换,可能会用到,一个通道为实数,一个通道为虚数,主要是编程方便。RGB555是16位的,2个字节,5+6+5,第一字节的前5位是R,后三位+第二字节是G,第二字节后5位是B,可见对原图像进行压缩了。
3. 通道的是彩色图像,比如RGB图像。
4. 通道的图像是RGBA,是RGB加上一个A通道,也叫alpha通道,表示透明度。PNG图像是一种典型的4通道图像。alpha通道可以赋值0到1,表示透明到不透明。
- 局部自适应阀值二值化:
void cvAdaptiveThreshold(InputArray src, OutputArray dst, double maxValue, int adaptiveMethod, int thresholdType, int blockSize, double C )
参数说明:
- src:输入图像.
- dst:输出图像.
- max_value :使用 CV_THRESH_BINARY 和CV_THRESH_BINARY_INV 的最大值.adaptive_method :自适应阈值算法使用:CV_ADAPTIVE_THRESH_MEAN_C 或CV_ADAPTIVE_THRESH_GAUSSIAN_C .
- threshold_type :取阈值类型:必须是CV_THRESH_BINARY或者CV_THRESH_BINARY_INV.
- block_size :用来计算阈值的象素邻域大小: 3, 5, 7, …
- param1 :与方法有关的参数。对方法 CV_ADAPTIVE_THRESH_MEAN_C 和 CV_ADAPTIVE_THRESH_GAUSSIAN_C,它是一个从均值或加权均值提取的常数,尽管它可以是负数。
函数cvAdaptiveThreshold将灰度图像转换为二值图像,采用以下共识:
threshold_type=CV_THRESH_BINARY:
dst(x,y) = max_value, if src(x,y)>T(x,y)
0, otherwise
threshold_type=CV_THRESH_BINARY_INV:
dst(x,y) = 0, if src(x,y)>T(x,y)
max_value, otherwise
其中 TI 是为每一个象素点单独计算的阈值
- 对方法 CV_ADAPTIVE_THRESH_MEAN_C,先求出块中的均值,再减掉param1。
- 对方法 CV_ADAPTIVE_THRESH_GAUSSIAN_C ,先求出块中的加权和(gaussian),再减掉param1。
- 当block_size比较小的时候,相当于提取边缘,该参数是决定局部阀值的block的大小,当block很小时,如block_size=3,5,7时,'自适应'的程度很高,即容易出现block里面的像素值都差不多,这样便无法二值化,而只能在边缘等梯度大的地方实现二值化,结果显得它是边缘提取函数。当把block_size设为比较大的值时,如block_size=21,31,51时,cvAdaptiveThreshold便是二值化函数了。
这里需要注意的是block_size参数,它只能为奇数,否则就会崩溃,error:blockSize%2 == 1 && blockSize > 1 (blockSize为奇数,且不能为负数)报错信息如下:

下面是两种阀值二值化的效果对比:
- 全局固定阀值二值化
- 局部自适应阀值二值化
 本例中使用的是局部自适应阀值二值化处理。
本例中使用的是局部自适应阀值二值化处理。
四. 腐蚀(Erode)
腐蚀:图像处理操作中的最基本形态学操作有二:腐蚀与膨胀(Erosion 与 Dilation),它们的应用非常广泛:
- 腐蚀可以分割(isolate)独立的图像元素,膨胀用于连接(join)相邻的元素,这也是腐蚀和膨胀后图像最直观的展现
- 去噪:通过低尺寸结构元素的腐蚀操作很容易去掉分散的椒盐噪声点
- 图像轮廓提取:腐蚀操作
- 图像分割
- ……
腐蚀在形态学操作家族里是膨胀操作的孪生姐妹。它提取的是内核覆盖下的相素最小值。进行腐蚀操作时,将内核划过图像,将内核覆盖区域的最小相素值提取,并代替锚点位置的相素。进行腐蚀操作的函数是erode。 它接受了三个参数:
- src: 原图像
- erosion_dst: 输出图像
- element: 腐蚀操作的内核。 如果不指定,默认为一个简单的 矩阵。否则,我们就要明确指定它的形状,可以使用函数getStructuringElement:
获取自定义核,以及进行腐蚀操作
cv::Mat erodeElement = getStructuringElement(cv::MORPH_RECT, cv::Size(5,5));
cv::erode(cvImage, cvImage, erodeElement);
腐蚀处理效果图效果图:
 OK...要的就是这种效果,接着进行轮廓检测。这里有必要说明一点:腐蚀和膨胀是对白色部分(高亮部分)而言的,不是黑色部分。
OK...要的就是这种效果,接着进行轮廓检测。这里有必要说明一点:腐蚀和膨胀是对白色部分(高亮部分)而言的,不是黑色部分。
五. 轮廓检测
使用函数:
findContours(InputOutputArray image,OutputArrayOfArrays contours,OutputArray hierarchy, int mode, int method,Point offset-Point())
参数说明:
- InputOutputArray image -- 单通道图像矩阵,可以是经过Canny,拉普拉斯等边缘检测算子处理过的二值图像,我这里使用的是经过腐蚀处理的二值图
- OutputArrayOfArrays contours -- 定义为vector<vector
>类型,是一个向量,并且是一个双重向量,向量内每个元素保存了一组由连续的Point点构成的点的集合的向量,每一组Point 点集就是一个轮廓。 - OutputArray hierarchy -- 定义为vector
类型,Vec4i是Vec<int,4>的别名,定义了一个'向量内每一个元素包含了4个int型变量’的向量。所以从定义看,hierarchy也是一个向量,向量内每个元素保存了一个包含4个int整型的数组。向量hierarchy内的元素和轮廓向量contours内的元素是一一对应的,向量的内容相同。hierarchy向量内每一个元素的4个int型变量hierarchy[i][0] ~ hierarchy[i][3],分别表示i个轮廓的后一个轮廓,前一个轮廓,父轮廓,内嵌轮廓的索引编号。如果当前轮廓没有对应的后一个轮廓、前一个轮廓、父轮廓或内嵌轮廓的话,则hierarchy[i][0] ~hierarchy[i][3]的相应位被设置为默认值-1。 - int modeint -- 可以定义轮廓的检索模式:
- CV_RETR_EXTERNAL只检测最外围轮廓,包含在外围轮廓内的内围轮廓被忽略
- CV_RETR_LIST:检测所有的轮廓,包括内围、外围轮廓,但是检测到的轮廓不建立等级关系,彼此之间独立,没有等级关系,这就意味着这个检索模式下不存在父轮廓或内嵌轮廓,所以hierarchy向量内所有元素的第3、第4个分量都会被置为-1。
- CV_RETR_CCOMP:检测所有的轮廓,但所有轮廓只建立两个等级关系,外围为顶层,若外围内的内围轮廓还包含了其他的轮廓信息,则内围内的所有轮廓均归属于顶层。
- CV_RETR_TREE:检测所有轮廓,所有轮廓建立一个等级树结构。外层轮廓包含内层轮廓,内层轮廓还可以继续包含内嵌轮廓。
- int method -- 定义轮廓的近似方法:
- CV_CHAIN_APPROX_NONE:保存物体边界上所有连续的轮廓点到contours向量内
- CV_CHAIN_APPROX_SIMPLE:仅保存轮廓的拐点信息,把所有轮廓拐点处的点保存入contours向量内,拐点与拐点之间直线段上的信息点不予保留
- CV_CHAIN_APPROX_TC89_L1,CV_CHAIN_APPROX_TC89_KCOS使用teh-Chinl chain 近似算法
- Point offset -- 偏移量,所有轮廓信息相对于原始图像对应点的偏移量,相当于在每一个检测点的轮廓点上加上该偏移量,并且Point可以是负值。
使用之前先定义容器参数,用以储存检测到的所有轮廓数据。
/*---------轮廓检测---------*/
- (IBAction)nextAction:(UIButton *)sender {
std::vector<std::vector<cv::Point>> contours; //定义一个容器来存储所有检测到的轮廊
std::vector<cv::Vec4i> hierarchy;
// 轮廓检测函数
cv::findContours(cvImage, contours,hierarchy, CV_RETR_TREE, CV_CHAIN_APPROX_NONE, cvPoint(0, 0));
long max_Index = contours.size();
if (index < max_Index-1) {
++index;
}
[self takePictureForRectWith:contours];
}
容器内数据较多,这里只打印小部分:

六. 提取身份证号码区域
在获取到图片中所有内容的轮廓集合之后,可以利用数据定位到身份证号码所在的区域,然后在原图上进行截取。截取成功之后转换为灰度图,再二值化处理,最后进行识别。
 容器内数据定位到的区域(省略了部分),依据上述处理过程,我们一步步去实现。
容器内数据定位到的区域(省略了部分),依据上述处理过程,我们一步步去实现。
- 首先遍历容器contours,然后使用boundingRect函数获取矩形边界框。
/*-------取出身份证号码区域-------*/
- (void)takePictureForRectWith:(std::vector<std::vector<cv::Point>>)contours{
// 取出对应的区域
std::vector<cv::Rect> rects;
cv::Rect numberRect = cv::Rect(0,0,0,0);
std::vector<std::vector<cv::Point>>::const_iterator itContours = contours.begin();
long max_Index = contours.size();
if (max_Index > 0) {
cv::Rect rect = cv::boundingRect(itContours[index]);
numberRect = rect;
printf("X:%d - Y:%d - width:%d - height:%d \n",rect.x,rect.y,rect.width,rect.height);
}
if (numberRect.width != 0 && numberRect.height != 0) {
[self showUIImageWithRect:numberRect];
}
}
- 这里定位身份证号码区域的算法原理:如果新的区域范围宽度大于已赋值区域宽度,并且宽度为高度的三倍则赋予新值。如下图身份证号码区域:
 定位到目标区域之后,可以从原图截取了,之后进一步做灰度化,二值化处理,然后显示,并进行识别。
定位到目标区域之后,可以从原图截取了,之后进一步做灰度化,二值化处理,然后显示,并进行识别。
/*-------截取目标图--------*/
- (void)showUIImageWithRect:(cv::Rect)numberRect {
// 目标图像
cv::Mat resultImage;
// 原图 -> Mat
cv::Mat matImage;
UIImageToMat(image, matImage);
// 取到对应Rect的目标图像
resultImage = matImage(numberRect);
// 将目标图像灰度处理
cv::cvtColor(resultImage, resultImage, cv::COLOR_BGR2GRAY);
// 二值化
cv::adaptiveThreshold(resultImage, resultImage, 255, CV_ADAPTIVE_THRESH_GAUSSIAN_C, CV_THRESH_BINARY, 31, 40);
[self cv_MatToUIImageWithMat:resultImage];
}
/*-------显示目标图--------*/
- (void)cv_MatToUIImageWithMat:(cv::Mat)Mat {
// Mat -> UIImage
UIImage *newImage = MatToUIImage(Mat);
// 供识别的Image赋值
dis_Img = newImage;
// 显示UIImage图
CGFloat width = newImage.size.width;
CGFloat height;
CGFloat scale = newImage.size.height/newImage.size.width;
width = width > [UIScreen mainScreen].bounds.size.width ? [UIScreen mainScreen].bounds.size.width: width;
height = width * scale;
CGRect imgRect = CGRectMake(([UIScreen mainScreen].bounds.size.width - width) * 0.5, 200, width, height);
self.imageView.frame = imgRect;
self.imageView.image = newImage;
}
显示截取目标图
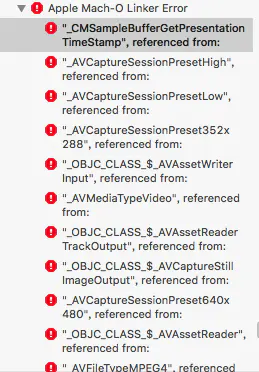
到这里,基于OpenCV的前期处理已经完成,接下来是另外一个框架的使用了:光学字符识别(Tesseract),一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎。Tesseract十分强大,但有以下几点局限性:
- 不像其他OCR引擎(例如美国邮政业用于分类邮件的),Tesseract不能识别手写,而且只能识别一共大约64种字体的文本。
- Tesseract需要一些处理来改善OCR结果,图像需要被放缩,图像有非常多的差异,另外还有水平排布的文字。
- 最后,Tesseract仅仅支持Linux,Windows,Mac OS X,并不支持iOS系统,所以网上也就有一套Tesseract OCR的Objective-C封装了 -- TesseractOCRiOS,也可以被用于swift写的项目上。
七. TesseractOCRiOS
首先还是环境搭建了,直接pod就可以,import头文件 <TesseractOCR/TesseractOCR.h>,build:
这是缺少依赖库了,一个个导入吧:
依赖库,再build一下,没问题。可以开始识别了,贴上代码及注释:
- 初始化tesseract为一个新的G8Tesseract对象
- Tesseract将从.traineddata文件中寻找你在该参数中指定的语言,指定为eng和fra将从"eng.traineddata" 和 "fra.traineddata"包含的数据中分别检测英文和法文,法语转换数据(trained data)已经被包含到该工程中了,因为本教程中你将使用的示例诗词中包含一部分法语(Très romantique!),法语中的重读符号不在英语字母集中,因此为了能展示出这些重读符号,你需要连接法语的.traineddata文件。将法语数据包含进来也是很好的,因为.traineddata中有一部分涉及到了语言词汇。
G8Tesseract* tesseract = [[G8Tesseract alloc] initWithLanguage:@"eng"];
- 你可以指定三种不同的OCR工作模式:.TesseractOnly是最快但最不精确的方法;.CubeOnly要慢一些,但更精确,因为它使用了更多的人工智能;.TesseractCubeCombined同时使用.TesseractOnly和.CubeOnly来提供最精确的结果,不过这也导致了它成为三种工作方式中最慢的一种。
tesseract.engineMode = G8OCREngineModeTesseractCubeCombined;
- Tesseract假定处理的文字是均匀的一段文字,但是你的样例诗中分了多段。Tesseract的pageSegmentationMode可以让它知道文字是怎么样被划分的。所以这里设置pageSegmentationMode为.Auto来支持自动页划分(automatic page segmentation),这样Tesseract就有能力识别段落分割了。
tesseract.pageSegmentationMode = G8PageSegmentationModeAuto;
- 这里你通过设定maximumRecognitionTime来限制Tesseract识别图片的时间为一有限的时间。不过这样设定以后,只有Tesseract引擎被限制了,如果你正在使用.CubeOnly 或 .TesseractCubeCombined工作模式,那么即使Tesseract已经达到了maximumRecognitionTime指定的时间,立体引擎(Cube engine)依然会继续处理。
tesseract.maximumRecognitionTime = 30.0;
// 开始识别
CFAbsoluteTime start = CFAbsoluteTimeGetCurrent();
- 如果文字和背景相差很大,那么你将得到Tesseract处理的最好结果。Tesseract有一个内置的滤镜,g8_blackAndWhite(),降低图片颜色的饱和度,增加对比度,减少亮度。这里你在Tesseract图像识别过程开始之前,将滤镜处理后的图像赋值给Tesseract对象的image属性。
tesseract.image = [dis_Img g8_blackAndWhite];
NSString *dis_str = tesseract.recognizedText;
// 识别结束
CFAbsoluteTime end = CFAbsoluteTimeGetCurrent();
最后的识别效果就是文章开头所呈现的,在本例中,对于二值化处理,目标区域的提取算法都有一定的局限性,实用条件较为苛刻。如果在实际开发中运行,还需要结合其它一些技术,对图片进行预处理,以提高识别的成功率及准确率,这篇身份证号码识别就讲到这。
分享一下运用TesseractOCRiOS对整张图片进行文字识别的效果:
 最后如果有需求本次源码的点击下载,里面注释比较详细,如果文中有讲解不到位或者有错误的地方欢迎留言讨论,你的Star和Fork就是我的动力,谢谢!
最后如果有需求本次源码的点击下载,里面注释比较详细,如果文中有讲解不到位或者有错误的地方欢迎留言讨论,你的Star和Fork就是我的动力,谢谢!
参考
- Opencv之图像灰度化
- 颜色空间转换
- 常用的二值化算法
- Mat之通道的理解
- 图像卷积与滤波的一些知识点
- 腐蚀与膨胀(Eroding and Dilating)
- findContours函数参数详解
- findContours层次结构 Tesseract OCR(光学字符识别)
本文由 创作,采用 知识共享署名4.0 国际许可协议进行许可。本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名。最后编辑时间为: 2020/11/13 08:14