异常在Java中是非常重要的一个内容,了解异常有助于我们写出更加健壮的代码,本文将探讨一下几个问题:
- 异常是怎么被JVM捕获的?
- 新建异常实例是否耗时?为什么会耗时?是否能够避免?
- 为什么不推荐使用printStackTrace()打印异常信息?
- spring jdbc运行时异常种类概要
- 什么时候应该抛出数据库运行时异常
1. 异常怎么被JVM捕获的
在了解这个之前首先介绍下java的异常表(Exception table),异常表是JVM处理异常的关键点,在java类中的每个方法中,会为所有的try-catch语句,生成一张异常表,存放在字节码的最后,该表记录了该方法内每个异常发生的起止指令和处理指令。了解了异常表后,看下面这段java代码:
public void catchException() {
long l = System.nanoTime();
for (int i = 0; i < testTimes; i++) {
try {
throw new Exception();
} catch (Exception e) {
//nothing to do
}
}
System.out.println("抛出并捕获异常:" + (System.nanoTime() - l));
}
在这段try-catch结构的代码片段中,在try语句中抛出了一个异常并catch捕获该异常,对比下图该代码段的java字节码(使用javap -c命令)
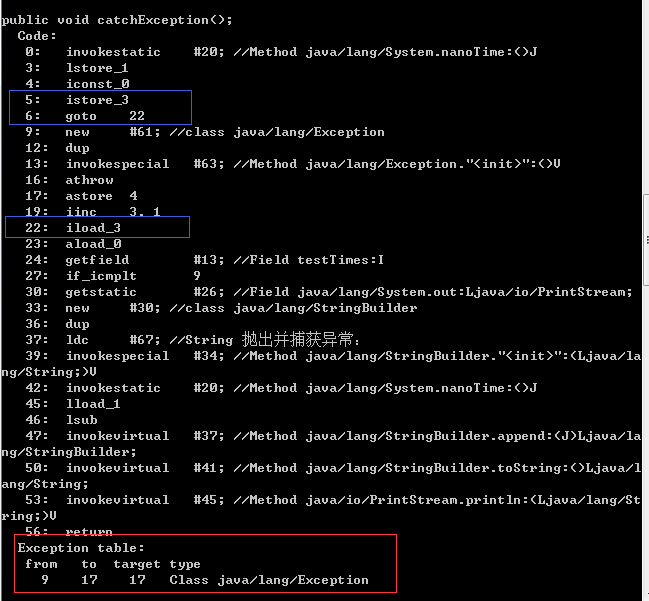 下面请结合java代码和生成的字节码来看下面的指令分析:
下面请结合java代码和生成的字节码来看下面的指令分析:
- 0-4号: 执行try前面的语句
- 5号: 执行try语句前保存现场
- 6号: 执行try语句后跳转指令行,图中表示跳转到22
- 9-17号: try-catch代码生成指令,结合红色框图异常表,表示9-17号指令若有Exception异常抛出就执行17行指令.
- 16号: athrow 表示抛出异常
- 17号: astore 表示jvm将该异常实例存储到局部变量表中
- 22号: 恢复try语句执行前保存的现场
对比指令分析,再结合使用try-catch代码分析:
- 若try没有抛出异常,则继续执行完try语句,跳过catch语句,此时就是从指令6跳转到指令22.
- 若try语句抛出异常则执行指令17,将异常保存起来,若异常被方法抛出,调用方拿到异常可用于异常层次索引。
- 通过以上的分析,可以知道JVM是怎么捕获并处理异常,其实就是使用goto指令来做上下文切换,但是,异常真的像平时大家所认为的那样耗时吗?且看第二部分
2. 异常是否耗时?为什么会耗时?
想要知道异常是否耗时,最简单的方法就是来一段代码测试下,如下代码片段
public class ExceptionTest {
private int counts;
public ExceptionTest(int counts) {
this.counts = counts;
}
public void newObject() {
long l = System.nanoTime();
for (int i = 0; i < counts; i++) {
new Object();
}
System.out.println("建立基础对象:" + (System.nanoTime() - l));
}
public void newOverridObj() {
long l = System.nanoTime();
for (int i = 0; i < counts; i++) {
new Child();
}
System.out.println("建立继承对象:" + (System.nanoTime() - l));
}
public void newException() {
long l = System.nanoTime();
for (int i = 0; i < counts; i++) {
new Exception();
}
System.out.println("新建异常对象:" + (System.nanoTime() - l));
}
public void catchException() {
long l = System.nanoTime();
for (int i = 0; i < counts; i++) {
try {
throw new Exception();
} catch (Exception e) {
//nothing to do
}
}
System.out.println("抛出并捕获异常:" + (System.nanoTime() - l));
}
public static void main(String[] args) {
ExceptionTest test = new ExceptionTest(10000);
test.newObject();
test.newOverridObj();
test.newException();
test.catchException();
}
}
在运行1W次的耗时输出为(单位:纳秒):
建立基础对象: 2,181,164
建立继承对象: 4,920,114
新建异常对象: 22,716,147
抛出并捕获异常: 101,761,933
很清晰的可以看到新建一个异常对象比新建一个普通对象在耗时上多一个数量级,抛出并捕获异常的耗时比新建一个异常在耗时上也要多一个数量级。答案已经很清晰明了,创建一个异常对象却是要比一个普通对象耗时多,捕获一个异常耗时更甚。为什么新建一个异常对象这么耗时?且看源码:在java中,所有的异常都继承自Throwable类,Throwable的构造函数
public Throwable() {
fillInStackTrace();
}
public synchronized Throwable fillInStackTrace() {
if (stackTrace != null ||
backtrace != null /* Out of protocol state */ ) {
fillInStackTrace(0);
stackTrace = UNASSIGNED_STACK;
}
return this;
}
private native Throwable fillInStackTrace(int dummy);
有个nativ方法public synchronized native Throwable fillInStackTrace();,这个方法会存入当前线程的堆栈信息。也就是说每次创建一个异常实例都会把堆栈信息存一遍。这就是时间开销的主要来源了。这个时候我们可以下一个结论:新建异常对象比创建一个普通对象是要更加的耗时。
能避开创建异常的这个耗时吗?答案是可以的,如果在程序中我们不关心异常抛出的异常占信息,我们可以自己定义一个异常继承自已有的异常类型,并写一个方法覆盖掉fillInStackTrace方法就行了。
3. 使用printStackTrace()打印异常信息分析
还是通过源码来分析:
public void printStackTrace() {
printStackTrace(System.err);
}
public void printStackTrace(PrintStream s) {
synchronized (s) {
s.println(this);
StackTraceElement[] trace = getOurStackTrace();
//for循环stack trace,at……信息是不是很熟悉
for (int i=0; i < trace.length; i++)
s.println("\tat " + trace[i]);
Throwable ourCause = getCause();
if (ourCause != null)
ourCause.printStackTraceAsCause(s, trace);
}
}
//递归函数,打印cause信息
private void printStackTraceAsCause(PrintStream s,StackTraceElement[] causedTrace)
{
// assert Thread.holdsLock(s);
// Compute number of frames in common between this and caused
StackTraceElement[] trace = getOurStackTrace();
int m = trace.length-1, n = causedTrace.length-1;
while (m >= 0 && n >=0 && trace[m].equals(causedTrace[n])) {
m--; n--;
}
int framesInCommon = trace.length - 1 - m;
//熟悉的输出格式
s.println("Caused by: " + this);
for (int i=0; i <= m; i++)
s.println("\tat " + trace[i]);
if (framesInCommon != 0)
s.println("\t... " + framesInCommon + " more");
// Recurse if we have a cause
Throwable ourCause = getCause();
//递归
if (ourCause != null)
ourCause.printStackTraceAsCause(s, trace);
}
在这段代码中可以看到在调用printStackTrace()方法的过程中会去爬栈,包括一个for循环和一个递归调用,当异常抛出的层次比较深的时候这个是非常耗时。了解了异常捕获和开销,下面看看使用spring jdbc运行时主要的异常种类
4. spring jdbc运行时异常种类概要
先上一张图
 数据库运行时异常的父类是DataAccessException,这个类包括三个子类,由于在我们的工程项目中是使用tddl直接对数据连接,我们一般只关系数据库对数据的操作(select、insert、update、delete),所以图中第二种和第三种异常本节不做讨论,主要看看第一种异常的种类与发送的情形,下面列出了
数据库运行时异常的父类是DataAccessException,这个类包括三个子类,由于在我们的工程项目中是使用tddl直接对数据连接,我们一般只关系数据库对数据的操作(select、insert、update、delete),所以图中第二种和第三种异常本节不做讨论,主要看看第一种异常的种类与发送的情形,下面列出了
- CleanupFailureDataAccessException: 数据库操作结束后的清理工作出现异常(关闭连接等)
- DataIntegrityViolationException: 尝试插入或更新数据后,约束问题上的一些抛出(比如重复插入唯一键值)
- DataRetrievalFailureException: 数据检索查找时候抛出一些异常(比如通过一个标识查找数据引发IO等问题)
- DataSourceLookupFailureException: 指定的数据源无法得到抛出异常
- InvalidDataAccessApiUsageException: 使用了不正确的数据库API抛出异常()
- InvalidDataAccessResourceUsageException: 使用数据库资源不正确抛出异常,例如使用错误的SQL
- NonTransientDataAccessResourceException: 资源访问永久失败会抛出异常
- PermissionDeniedDataAccessException: 没有权限访问数据的某些表字段会抛出异常
- UncategorizedDataAccessException: 其他的一些不能使用更准确的描述的异常
5. 什么时候应该抛出数据库运行时异常
本节主要是结合项目代码来讲,项目代码一般都分成三个部分:DAO、Service、Controller。其中DAO用来做数据库的基本操作(select、insert、update、delete),Service一般用来处理具体的业务逻辑、Controller来做http请求控制。
在代码中的DAO层面一般我们都没有对异常进行抛出,导致我们在Service层和Controller也没有关注过数据库操作的异常,最终异常都是被JVM捕获并输出,这样会带来一个不好的结果,就是我们在自己的代码中并没有掌控住数据库操作这部分代码的执行细节。
比如说,一张表用来存储店铺的动态,店铺ID和动态的发布时间为唯一主键。考虑到并发性,如果一个店铺在同一个时间来了2条动态,那么就会有一条动态会插入失败。而因为我们没有在DAO层去捕获唯一键插入失败异常,会使得在业务处理层Service没有关注到这种异常的产生。最终使得我们会忽略掉某其中的某一条动态,且不知道忽略的到底是哪一条!
有了上面这个例子,可以知道在insert和update语句上,如果唯一主键有可能在并发的情况下产生不可预料的结果那么我们应该在DAO层就抛出一个唯一主键冲突异常。这样在写业务逻辑的时候会需要我们必须捕获这个异常并做异常逻辑处理。
总结下,在DAO层,对于数据库操作可能引起的需要Service层来处理的异常,在DAO层的方法定义上必须显示的抛出异常。
参考资料:
- http://icyfenix.iteye.com/blog/857722
- http://itindex.net/detail/46560-spring-jdbc
- http://blog.csdn.net/p106786860/article/details/11795771
- http://www.cnblogs.com/chenssy/p/3438130.html
- http://happyenjoylife.iteye.com/blog/1061495
- http://www.zhihu.com/question/21405047
- http://www.blogjava.net/liudecai/archive/2009/04/08/264460.html
- http://itindex.net/detail/47791-exception-%E6%80%A7%E8%83%BD-%E9%97%AE%E9%A2%98
本文由 创作,采用 知识共享署名4.0 国际许可协议进行许可。本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名。最后编辑时间为: 2020/05/13 01:12