事情发生在16年了。当时系统beta版本进行上线前的性能压测时,发现进程的内存占用率会持续升高,与之而来的时,性能的接口性能的持续下降。最奇怪的是,停止压测后CPU和内存开销并没有恢复过来。记得之前发过博文,不知道怎么回事找不到了。应其他同事的要求,回忆一下当时的定位过程,再做一个简单分享。
在讲述整个过程前,请大家自备两个梯子:
- Java虚拟机的垃圾回收机制
- jmeter的基本使用知识 首先下载jmeter工具,感觉是一个轻量级的性能检测工具,很好用。有基于windows 的GUI版本,也有在linux上运行的命令行版本。 下载地址:http://jmeter.apache.org/download_jmeter.cgi
怪象简述
刚开始压测时,一切指标都是正常的,也达到了预期水平。
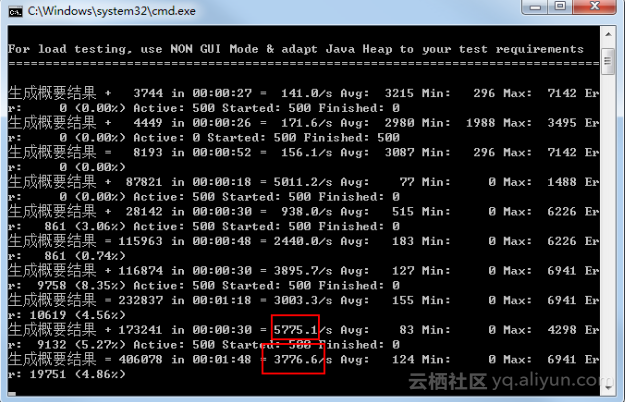 8小时后,性能直线下降。
8小时后,性能直线下降。
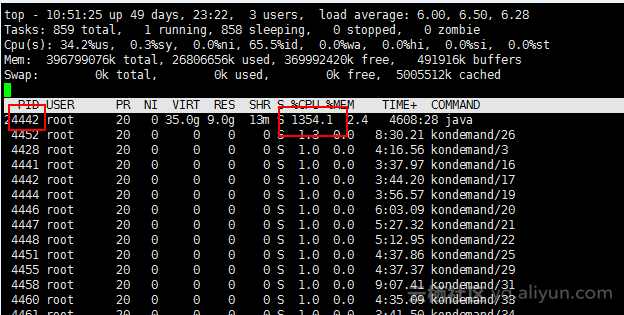
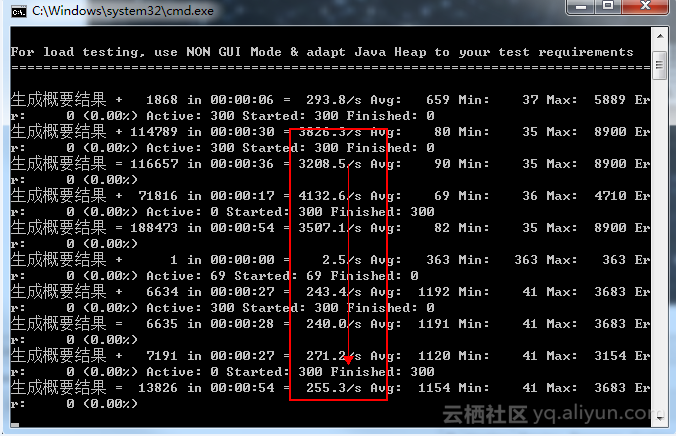 停止压测后,CPU和内存,仍然居高不下。 不要小看 2.4%的内存占用,这是200多G内存的物理服务器。(后面部署方式已切换为虚拟机的部署方式)
停止压测后,CPU和内存,仍然居高不下。 不要小看 2.4%的内存占用,这是200多G内存的物理服务器。(后面部署方式已切换为虚拟机的部署方式)
定位解决
- 首先命令行,看下java堆的情况:
jmap -heap 24442。看见年老区的内存被占满了。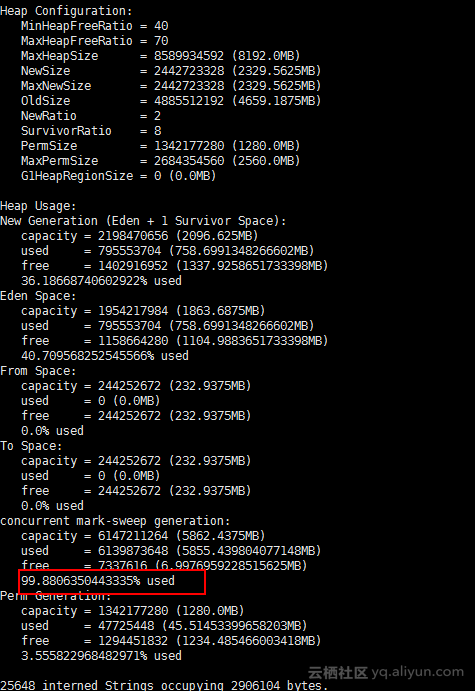
- 继续执行命令:
jsat –gcutil 24442 1000 5,看见年老区 使用率 100%,同时执行了12304次 FullGC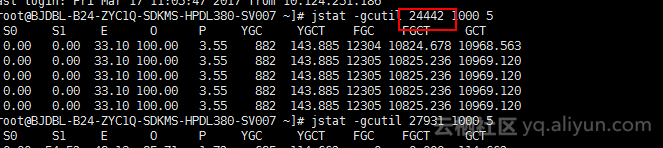
- 查看进程24442的线程信息:
ps –mp 24442 –o THREAD,tid,time。发现很多线程运行了好几个小时。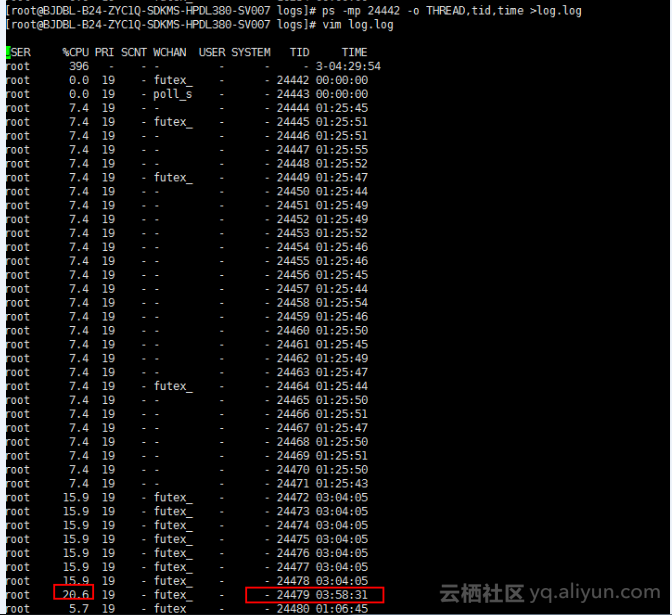 这个时候,明显怀疑有内存泄露了。再执行了两个命令(时间太久,没有找到截图了):
这个时候,明显怀疑有内存泄露了。再执行了两个命令(时间太久,没有找到截图了):
jstat -printcompilation -h3 24442
jmap -histo 24442
进一步发现,内存中某个类的实例数量和String类的实例数量,异常的多。最后在排查代码,找到了具体的类 及其使用逻辑。发现是由于队列的使用不当,造成了内存泄露
总结
本项目中,因为涉及频繁的小IO,所以开发同事期望通过生产者-队列-消费者的模型,用批量IO解决频繁小IO带来的资源开销。但在使用此模型时,忘计考虑了极限状态下,生产者的输入能力远大于消费者的消费能力时,会造成队列中的数据积压,进而造成内存泄露。但又因为常规情况下不会出现 此场景,所以很难发现这个bug。这个案例告诉我们:
- 对于一些关键接口,开发同事可以在完成开发后,自己用Jmeter压测一下,避免问题遗留到上线前期,造成巨大风险。
- Java仍然会有内存泄露的情况,使用类似数组、队列、栈等数据结构时,需要格外小心。
本文由 创作,采用 知识共享署名4.0 国际许可协议进行许可。本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名。最后编辑时间为: 2020/05/07 03:28