ElasticSearch实战:IK中文分词插件
1. 官方文档
- https://github.com/medcl/elasticsearch-analysis-ik
- https://code.google.com/archive/p/ik-analyzer/ 这里使用了腾讯云ElasticSearch服务,已默认集成了IK中文分词插件,因此安装过程略。
2. 我们为什么要使用IK分词插件
2.1 示例
我们以下面这个例子来做说明
1)创建索引与映射
PUT tencent
POST /tencent/bh8ank/_mapping
{
"properties": {
"content": {
"type": "text"
}
}
}
2)上传数据
POST /tencent/bh8ank/1
{
"content": "《王者荣耀》是由腾讯游戏天美工作室群开发并运行的一款运营在Android、IOS、NS平台上的MOBA类手机游戏"
}
POST /tencent/bh8ank/2
{
"content": "谁是行业的王者?国内细分行业龙头公司最全名单汇总"
}
POST /tencent/bh8ank/3
{
"content": "一个衰落行业的王者!还有多少荣耀?"
}
POST /tencent/bh8ank/4
{
"content": "王小二,1999年从中国人民大学新闻系毕业,以记者身份进入中央电视台"
}
3)检索数据
GET /tencent/bh8ank/_search
{
"query": {
"match": {
"content":"王者荣耀"
}
}
}
此时,我们的目的,是搜索包含“王者荣耀”的结果,但实际上,搜索结果是:
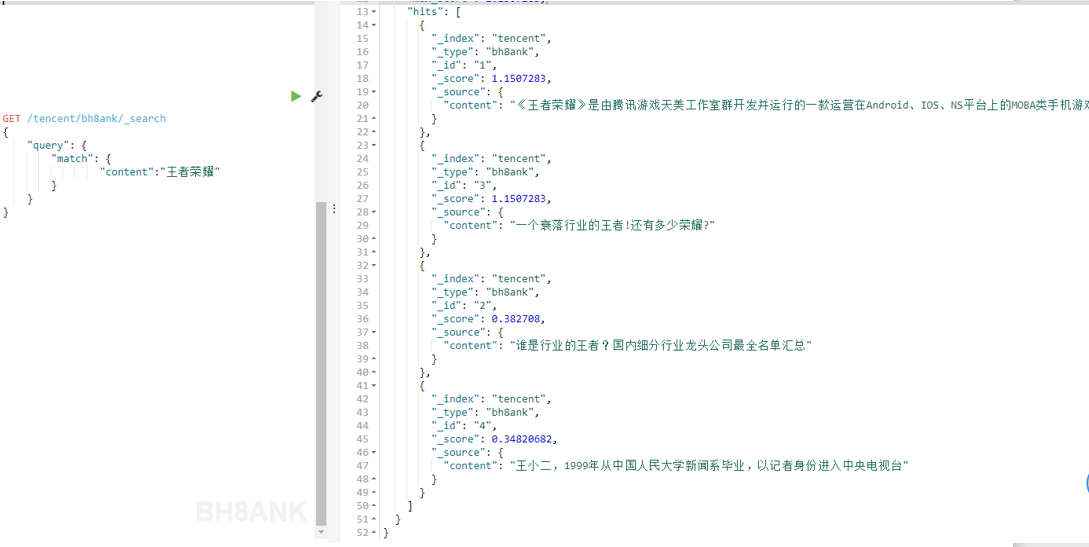 我们会发现,搜索结果中,有部分结果,并不是我们想要的。当数据量庞大时,这种问题的影响会更深。
我们会发现,搜索结果中,有部分结果,并不是我们想要的。当数据量庞大时,这种问题的影响会更深。
2.2 分析
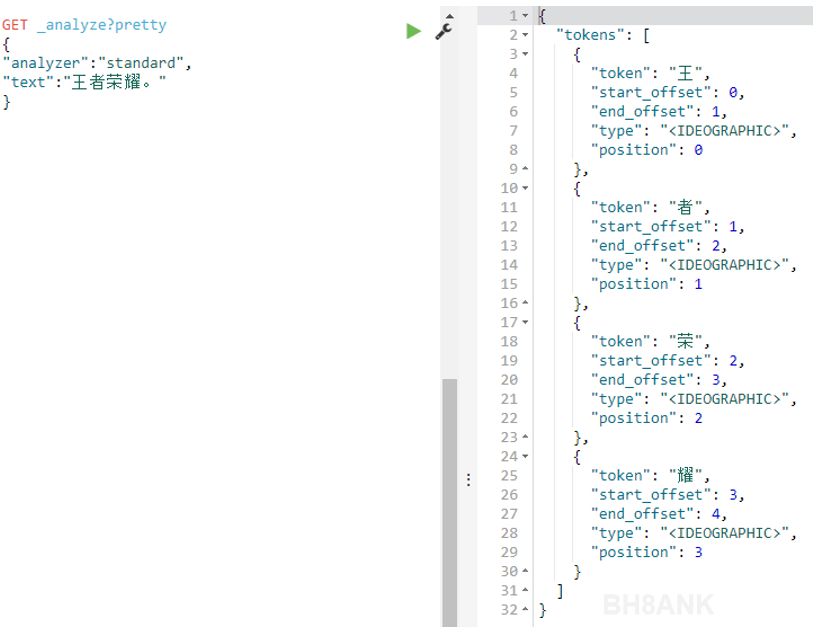
ElasticSearch对中文文本的搜索,支持度很有限。使用标准分词器的情况下,会将一段文本,分成多个“词”(word),每个“词”实际上对应单独的一个汉字。如下图,标准分词器将“王者荣耀”分为了4个独立的汉字。所以,上一步中,检索结果返回了所有包含这4个独立汉字的内容。
 那么问题来了,如果我们在检索“王者荣耀”时,只想要完整包含了“王者荣耀”这个词的结果,需要怎么办呢?
那么问题来了,如果我们在检索“王者荣耀”时,只想要完整包含了“王者荣耀”这个词的结果,需要怎么办呢?
我们需要一款支持中文的分词器,根据我们的需求,对中文进行分词。比如说,我们在上面检索之前,将“王者荣耀”设定为一个整体的、不可拆分的“词”,在检索时,只有完整包含“王者荣耀”这个词的结果才会被匹配,其他没有完整包含关键词的结果不能被匹配。
IK中文分词器就实现了上述的功能。 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。 从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本。 最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。 从3.0版本开始,IK发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。 在2012版本中,IK实现了简单的分词歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。
3. IK中文分词插件怎么使用
下面,我们创建一个新的集群,仍以上面的检索为例。使用IK后,重新检索。
3.1 创建索引和映射
PUT tencent
POST /tencent/bh8ank/_mapping
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_smart", ##指定索引内容使用ik_smart分词
"search_analyzer": "ik_smart" ##指定检索时,使用ik_smart分词
}
}
}
3.2 上传数据
POST /tencent/bh8ank/1
{
"content": "《王者荣耀》是由腾讯游戏天美工作室群开发并运行的一款运营在Android、IOS、NS平台上的MOBA类手机游戏"
}
POST /tencent/bh8ank/2
{
"content": "谁是行业的王者?国内细分行业龙头公司最全名单汇总"
}
POST /tencent/bh8ank/3
{
"content": "一个衰落行业的王者!还有多少荣耀?"
}
POST /tencent/bh8ank/4
{
"content": "王小二,1999年从中国人民大学新闻系毕业,以记者身份进入中央电视台"
}
3.3 检索数据
GET /tencent/bh8ank/_search
{
"query": {
"match": {
"content":"王者荣耀"
}
}
}
查看结果,我们发现,并没有像我们期待的那样只返回完整包含了“王者荣耀”的结果,而是依旧返回了很多我们不需要的结果。如下图:
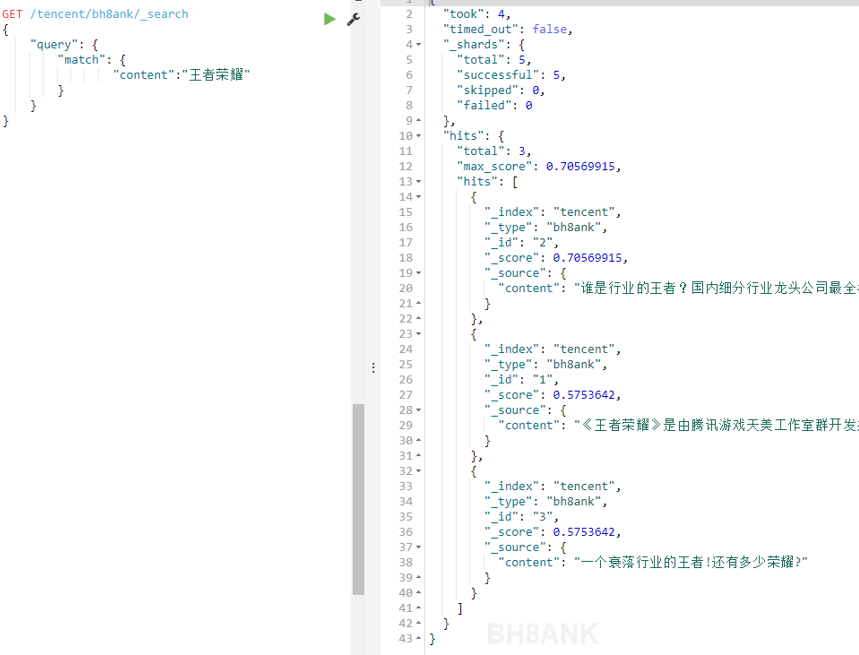
那么,问题出在哪里呢?
我们来看看,ik_smart是如何处理“王者荣耀”的,默认情况下,ik_smart对“王者荣耀”的拆分处理:
 如上图,ik_smart将“王者荣耀”拆分为了两个词“王者”和“荣耀”,因此,在上一步检索时,返回了所有包含这两个词的结果。
如上图,ik_smart将“王者荣耀”拆分为了两个词“王者”和“荣耀”,因此,在上一步检索时,返回了所有包含这两个词的结果。
那么,问题又来了,我们如何让IK插件准确地将“王者荣耀”识别为一个完整、独立的词呢?
3.4 上传启用词库
IK插件提供了启用词库的功能,这个功能,通过用户上传自定义的词库来实现。词库中定义的词,将不会被拆分,而是直接当做一个完整、独立的词来处理。
词库的制作需要注意两点:1,后缀以.dic格式命名;2,文件内容为utf-8编码,每行一个词
因此,我们需要制作一个词库,如下图:

然后上传至当前使用了ElasticSearch集群,如下图:
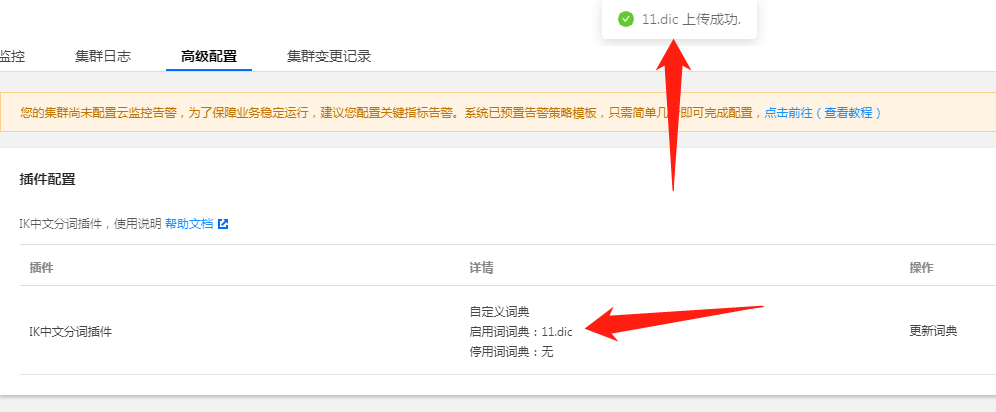
等待几分钟,词库生效。
3.5 再次检索数据
GET /tencent/bh8ank/_search
{
"query": {
"match": {
"content":"王者荣耀"
}
}
}
查看检索结果,如下图上传启用词库后的检索结果:
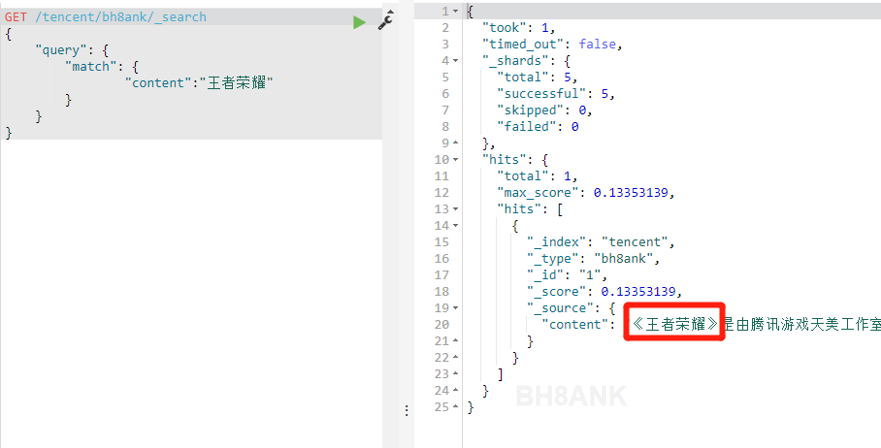
OK,现在只返回了我们需要的结果。
4. 总结
IK中文分词插件的其他相关内容这里暂不赘述。启用词库的作用,主要是方便用户对某些自定义的词组进行统一处理,避免因拆分过度导致出现非期望的检索结果。
本文由 创作,采用 知识共享署名4.0 国际许可协议进行许可。本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名。最后编辑时间为: 2020/06/30 01:30