将HTML文本转换为Markdown文本
package util;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.nodes.Node;
import org.jsoup.select.Elements;
/**
* Created by deng on 2018/8/9.
*/
public class Html2Md {
private Html2Md() {
}
public static String getMarkDownText(String html) {
StringBuilder result = new StringBuilder();
Document document = Jsoup.parseBodyFragment(html.replace(" ", ""));
// 遍历所有直接子节点
for (Node node : document.body().childNodes()) {
result.append(handleNode(node));
}
return result.toString();
}
/**
* 处理Node,目前支持处理p、pre、ul和ol四种节点
*
* @param node
* @return
*/
private static String handleNode(Node node) {
String nodeName = node.nodeName();
String nodeStr = node.toString();
switch (nodeName) {
case "p":
Element pElement = Jsoup.parseBodyFragment(nodeStr).body().getElementsByTag("p").first();
String pStr = pElement.html();
for (Element child : pElement.children()) {
pStr = handleInnerHtml(pStr, child);
}
return pStr + "\n";
case "pre":
return "```\n" + Jsoup.parseBodyFragment(nodeStr).body().text() + "\n```\n";
case "ul":
Element ulElement = Jsoup.parseBodyFragment(nodeStr).body().getElementsByTag("ul").first();
String ulStr = ulElement.html().replace("<li>", "- ").replace("</li>", "");
for (Element li : ulElement.getElementsByTag("li")) {
for (Element child : li.children()) {
ulStr = handleInnerHtml(ulStr, child);
}
}
return ulStr + "\n";
case "ol":
Element olElement = Jsoup.parseBodyFragment(nodeStr).body().getElementsByTag("ol").first();
String olStr = olElement.html();
Elements liElements = olElement.getElementsByTag("li");
for (int i = 1; i <= liElements.size(); i++) {
Element li = liElements.get(i - 1);
olStr = olStr.replace(li.toString(), li.toString().replace("<li>", i + ". ").replace("</li>", ""));
for (Element child : li.children()) {
olStr = handleInnerHtml(olStr, child);
}
}
return olStr + "\n";
// 非HTML元素
case "#text":
return "\n";
}
return "";
}
/**
* 处理innerHTML中的HTML元素,目前支持处理的子元素包括strong、img、em
*
* @param innerHTML
* @param child
* @return
*/
private static String handleInnerHtml(String innerHTML, Element child) {
switch (child.tag().toString()) {
case "strong":
innerHTML = innerHTML.replace(child.toString(), "**" + child.text() + "**");
break;
case "img":
String src = child.attr("src");
if (src.charAt(0) == '/') {
src = "https://leetcode-cn.com" + src;
}
innerHTML = innerHTML.replace(child.toString(), "");
break;
case "em":
innerHTML = innerHTML.replace(child.toString(), " *" + child.text() + "* ");
break;
default:
innerHTML = innerHTML.replace(child.toString(), child.text());
break;
}
return innerHTML;
}
}
利用jsoup解析HTML元素,思路如下:
- [1] 首先遍历HTML文档的直接子节点,直接子节点只包括p、pre、ul和ol四类元素,其中pre对应的是md中的代码片,ul对应md中的无序列表,ol对应md中的有序列表。实现见handleNode方法。
- [2] 其次解析每个一级子节点中的内部的HTML元素,包括strong、em、img,其中strong对应md中的粗体,em对应md中的斜体,img对应md中的图片。实现见handleInnerHTML方法。
运行效果:
public static void main(String[] args) {
System.out.println(Html2Md.getMarkDownText("<p>实现函数 ToLowerCase(),该函数接收一个字符串参数 str,并将该字符串中的大写字母转换成小写字母,之后返回新的字符串。</p>\n" +
"\n" +
"<p> </p>\n" +
"\n" +
"<p><strong>示例 1:</strong></p>\n" +
"\n" +
"<pre><strong>输入: </strong>"Hello"\n" +
"<strong>输出: </strong>"hello"</pre>\n" +
"\n" +
"<p><strong>示例 2:</strong></p>\n" +
"\n" +
"<pre><strong>输入: </strong>"here"\n" +
"<strong>输出: </strong>"here"</pre>\n" +
"\n" +
"<p><strong>示例</strong><strong> 3:</strong></p>\n" +
"\n" +
"<pre><strong>输入: </strong>"LOVELY"\n" +
"<strong>输出: </strong>"lovely"\n" +
"</pre>"));
}
运行输出如下图所示:
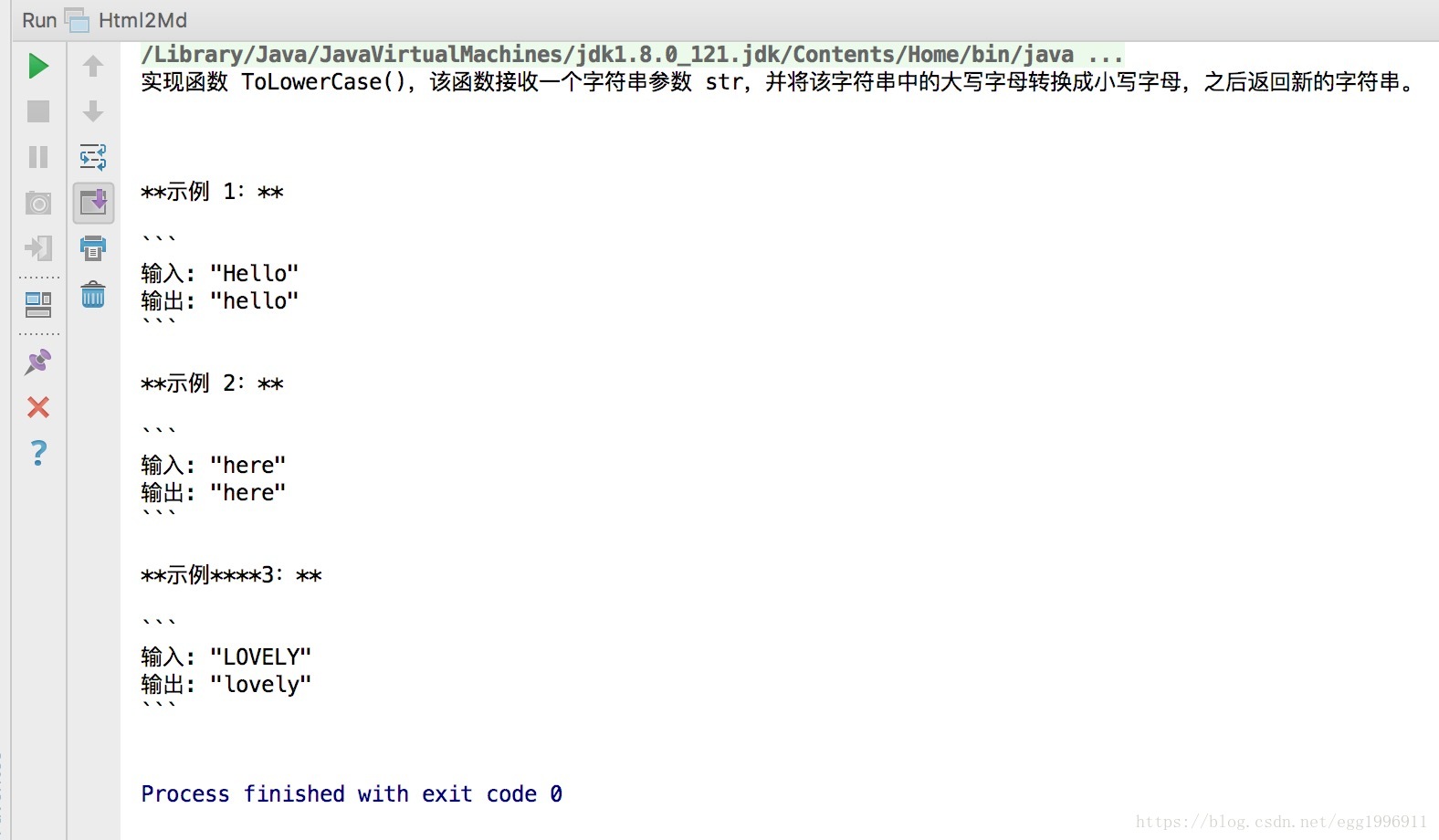
至此,便完成了对LeetCode编程题项目MD文件的构建。
本文由 创作,采用 知识共享署名4.0 国际许可协议进行许可。本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名。最后编辑时间为: 2020/05/18 01:12