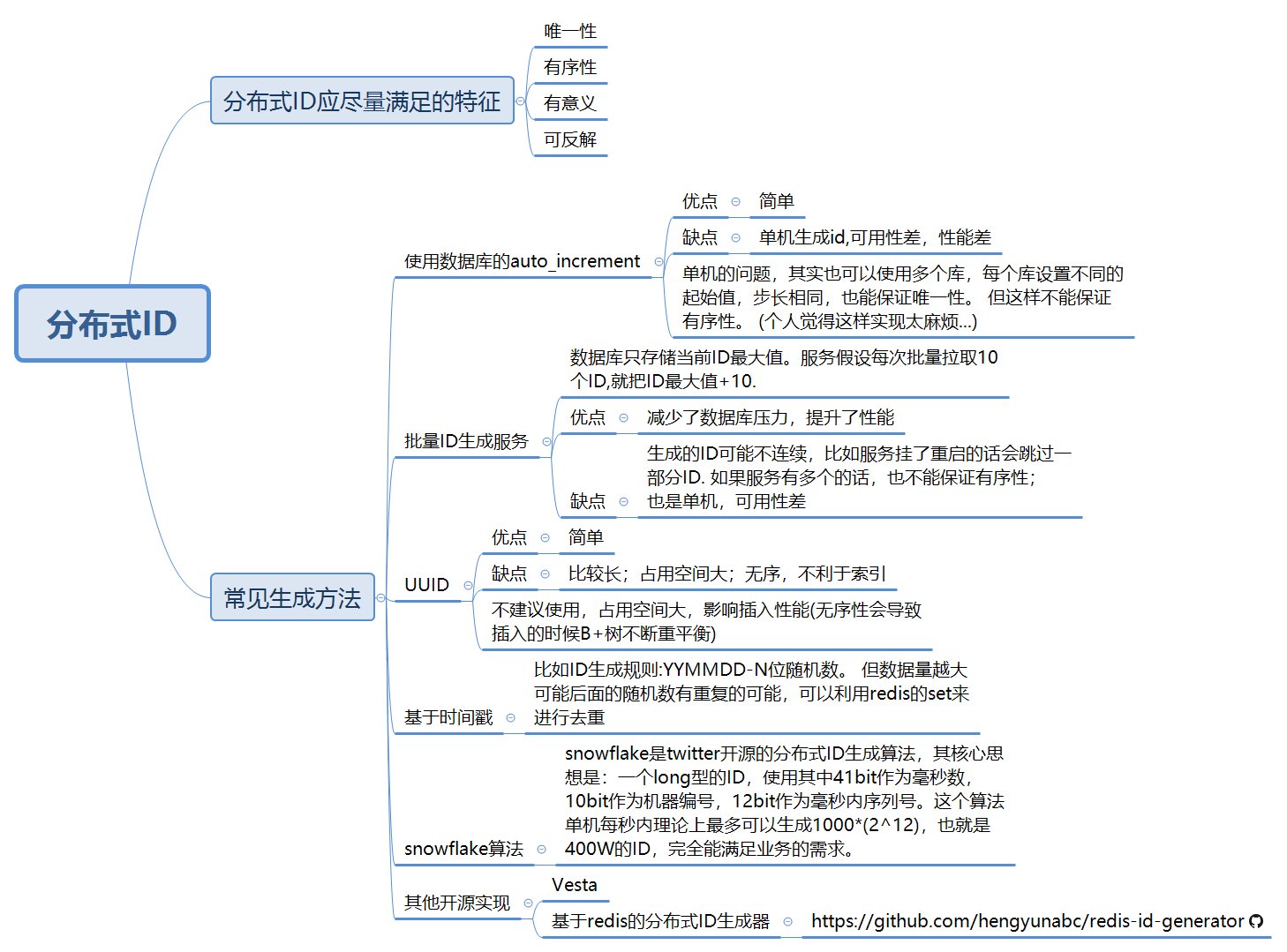
5 大分布式 ID 生成器优缺点简单对比
首选,不管是不是分布式系统,都有 ID 唯一的使用场景。而在分布式场景下,对 ID 的唯一性要求更严格!
常见的,我们上淘宝买东西的订单 ID,就是一种分布式 ID。淘宝,前期的订单 id 好像是 14 位,现在好像已经是 16 位,或者 18 位了吧。
以我们公司的订单 ID 为例,它有这几个特点。
- ID 全局唯一,不会重复
- ID 的增长支持分布式使用
- ID 要方便好记,并且通过 ID 能大概看出是什么时间创建的订单
- 订单 ID 最好还能追踪到销售员,或下单用户的 ID 等
- 增长的订单 ID 还不能让竞争对手发现你每天的业务量
针对第五项,浅显的问题就是不能让非核心运营者知道每天的订单量等信息。如果 ID 是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定 URL 即可;如果是订单号就更危险了,竞对可以直接知道我们一天的订单量。所以在一些应用场景下,会需要 ID 无规则、不规则。
所以,设计一个好的分布式 ID 生成器并不是那么容易的。于是网上也有很多大公司开源这类分布式 ID 生成器。我今天就抽个时间,扯一扯它们之间的不同点吧。
说到,分布式 ID,我们首选想到的可能就是 UUID 了。
UUID (Universally Unique Identifier) 的标准型式包含 32 个 16 进制数字,以连字号分为五段,形式为 8-4-4-4-12 的 36 个字符,示例:550e8400-e29b-41d4-a716-446655440000,到目前为止业界一共有 5 种方式生成 UUID。
UUID 的优点:性能非常高:本地生成,没有网络消耗。
UUID 的缺点:
- 不易于存储:UUID 太长,16 字节 128 位,通常以 36 长度的字符串表示,很多场景不适用。
- 信息不安全:基于 MAC 地址生成 UUID 的算法可能会造成 MAC 地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
- ID 作为主键时在特定的环境会存在一些问题,比如做 DB 主键的场景下,UUID 就非常不适用。MySQL 官方有明确的建议主键要尽量越短越好,36 个字符长度的 UUID 不符合要求;UUID 还对 MySQL 索引不利,如果作为数据库主键,在 InnoDB 引擎下,UUID 的无序性可能会引起数据位置频繁变动,严重影响性能。
snowflake
snowflake 我就不在介绍了,我直接说它的优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点:
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
MongDB 的 ObjectID 可以算作是和snowflake类似方法,通过“时间+机器码+pid+inc”共12个字节,通过4+3+2+3的方式最终标识成一个24长度的十六进制字符。
美团开源的Leaf
支持多种不同模式的生成策略
号段模式:该模式需要建 DB 表, 需要有专门的服务来提供获取 id 的接口, 存在网络延迟 Snowflake 模式:为了追求更高的性能,需要通过 RPC Server 来部署 Leaf 服务,那仅需要引入 leaf-core 的包,把生成 ID 的 API 封装到指定的 RPC 框架中即可
缺点,可能就是相对来说比较复杂。
sharding-jdbc
sharding-jdbc 是一个开源的主键生成组件。它的特点是简单易用,可以指定 workerId 或者不指定, 直接通过 jar 的方式引入即可。看它的名字就知道,它需要 DB 支持。
uid-generator
uid-generator 是百度开源的一个分布式 ID 生成器。需要建 DB 表, 需要有专门的服务来提供获取 id 的接口, 存在网络延迟。
本文由 创作,采用 知识共享署名4.0 国际许可协议进行许可。本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名。最后编辑时间为: 2021/04/19 08:50