JAVA识别身份证号码,H5识别身份证号码,tesseract-ocr识别
背景介绍:
这段时间正在做一个流动人口管理项目,其中要求使用H5网页拍照识别身份证,当时就蒙圈了,这不是APP的功能吗?产品为了快速迭代一直把APP的功能往H5上堆砌,没办法只有想办法解决了。 查了一些资料,发现除了收费的OCR(百度、云脉等等)比较好的并支持中文的就只有tesseract了,当然我收费的OCR我也没测试。 暂时决定使用tesseract了。
思路介绍
我的思路是这样的: 由H5调用摄像头—–>拍照上传到服务端—->服务端识别身份信息—–>服务端返回身份信息。
关键点提高识别率
因为整张身份证的识别率太过让人失望,所以必须对身份证图片进行处理。
假设我们能把身份证上的关键信息截取下来,是不是可以提高OCR的识别率?
 遵循这个假设开始测试。
遵循这个假设开始测试。
安装tesseract-ocr
我是在windows下进行测试的,Linux安装大家可以参考这篇博客Linux安装tesseract-ocr
windows下比较简单,下载程序安装就好,其中需要语言包的可以在安装选项中选择下载中文语言包,默认只有英文的。我安装的版本是tesseract-ocr3.01-1
Tesseract下载地址
因为wall的原因,这个网址无法直接打开,你懂的,所以使用迅雷下载吧。复制链接地址到迅雷新建任务,可以的。
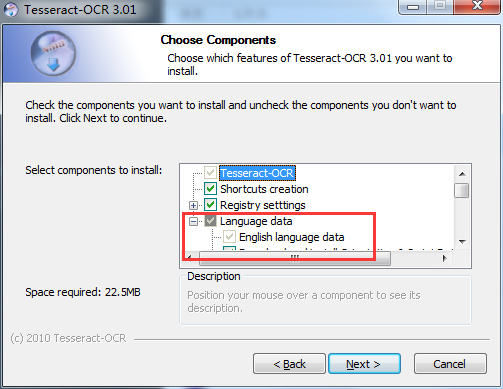 同意,下一步,选择语言包。我选了简体中文,但因为wall的原因没安装上!!!
中文的识别率太低了,这个大家也知道,结果跟产品扯了下皮,先做一版识别身份证号码的好了。这也是为什么我的标题是 识别身份证号码而不是识别身份信息了。
同意,下一步,选择语言包。我选了简体中文,但因为wall的原因没安装上!!!
中文的识别率太低了,这个大家也知道,结果跟产品扯了下皮,先做一版识别身份证号码的好了。这也是为什么我的标题是 识别身份证号码而不是识别身份信息了。
装完之后测试一下,找一个数字图片测试一下
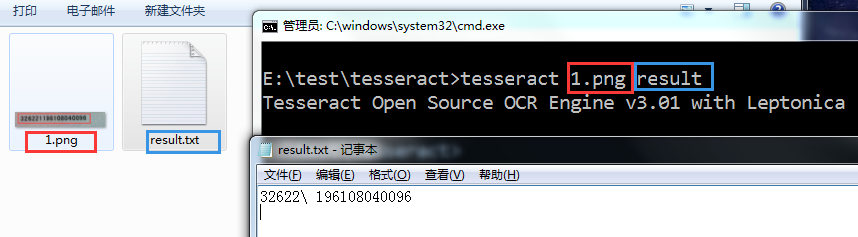
进入图片目录 运行cmd
tesseract 1.png result
- tesseract 是命令
- 1.png 是图片
- result 是需要生成结果的txt文档名,随便取
这结果令人堪忧啊。还好我们可以提高识别率的方法。
提高数字识别率,指定识别字符范围
找到安装目录下的tessdata\configs,打开其中的digits文件,使用文本编辑就好了。 我安装的在这个目录下 D:\Program Files (x86)\Tesseract-OCR\tessdata\configs\digits 。你会看见下面这句话,我们只要识别数字那就只留下数字和X好了。
tessedit_char_whitelist 0123456789-.
改为
tessedit_char_whitelist 0123456789X
保存 这个时候再测试一下,不过命令需要变一下,后面加上digits
tesseract 1.png result digits
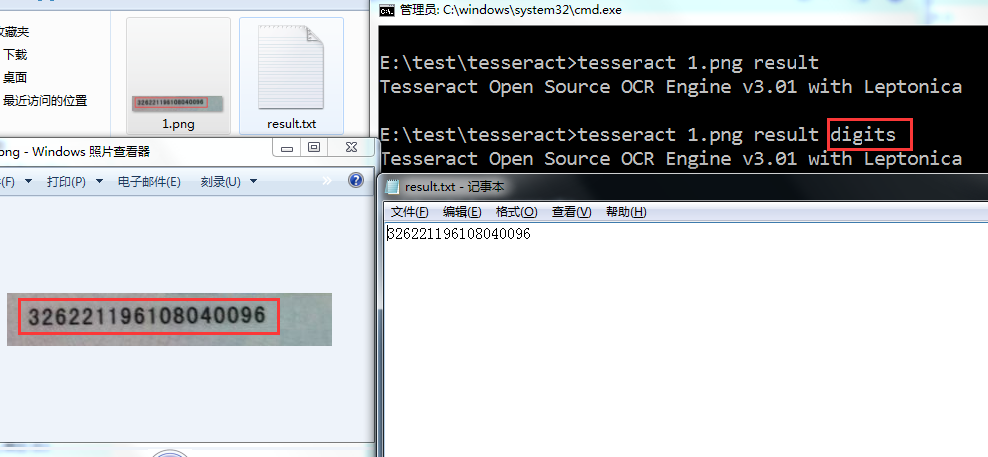 效果比较令人满意。
接下来就要使用Java调用识别命令了,其实很简单,就是使用java调用CMD命令。
效果比较令人满意。
接下来就要使用Java调用识别命令了,其实很简单,就是使用java调用CMD命令。
使用java调用识别命令
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
/**
* Created by Gavin Wang on 16-3-3.
*/
public class Tesseract {
private final String LANG_OPTION = "-l";
private final String EOL = System.getProperty("line.separator");
/**
* 文件位置我防止在,项目同一路径
*/
private String tessPath = new File("tesseract").getAbsolutePath();
/**
* @param imageFile
* 传入的图像文件
* @param imageFormat
* 传入的图像格式
* @return 识别后的字符串
*/
public String recognizeText(File imageFile) throws Exception
{
/**
* 设置输出文件的保存的文件目录
*/
File outputFile = new File(imageFile.getParentFile(), "output");
StringBuffer strB = new StringBuffer();
List<String> cmd = new ArrayList<String>();
String os = System.getProperty("os.name");
if(os.toLowerCase().startsWith("win")){
cmd.add("tesseract");
}else {
cmd.add("tesseract");
}
// cmd.add(tessPath + "\\tesseract");
cmd.add(imageFile.getName());
cmd.add(outputFile.getName());
// cmd.add(LANG_OPTION);
// cmd.add("chi_sim");
cmd.add("digits");
// cmd.add("eng");
// cmd.add("-psm 7");
ProcessBuilder pb = new ProcessBuilder();
/**
*Sets this process builder's working directory.
*/
pb.directory(imageFile.getParentFile());
// cmd.set(1, imageFile.getName());
pb.command(cmd);
pb.redirectErrorStream(true);
Process process = pb.start();
// Process process = pb.command("ipconfig").start();
// System.out.println(System.getenv().get("Path"));
// Process process = pb.command("D:\\Program Files (x86)\\Tesseract-OCR\\tesseract.exe",imageFile.getName(),outputFile.getName(),LANG_OPTION,"eng").start();
// tesseract.exe 1.jpg 1 -l chi_sim
// Runtime.getRuntime().exec("tesseract.exe 1.jpg 1 -l chi_sim");
/**
* the exit value of the process. By convention, 0 indicates normal
* termination.
*/
// System.out.println(cmd.toString());
int w = process.waitFor();
if (w == 0)// 0代表正常退出
{
BufferedReader in = new BufferedReader(new InputStreamReader(
new FileInputStream(outputFile.getAbsolutePath() + ".txt"),
"UTF-8"));
String str;
while ((str = in.readLine()) != null)
{
strB.append(str).append(EOL);
}
in.close();
} else
{
String msg;
switch (w)
{
case 1:
msg = "Errors accessing files. There may be spaces in your image's filename.";
break;
case 29:
msg = "Cannot recognize the image or its selected region.";
break;
case 31:
msg = "Unsupported image format.";
break;
default:
msg = "Errors occurred.";
}
throw new RuntimeException(msg);
}
new File(outputFile.getAbsolutePath() + ".txt").delete();
return strB.toString().replaceAll("\\s*", "");
}
}
注释掉的内容大家都可删掉,是我测试的时候遗留的 下面是main方法
import java.io.File;
import java.io.IOException;
/**
* Created by Gavin Wang on 16-3-3.
*/
public class Start {
public static void main(String[] args) throws Exception {
Tesseract("/1.png");
Tesseract("/2.png");
Tesseract("/3.png");
Tesseract("/4.png");
Tesseract("/5.png");
Tesseract("/6.png");
}
private static void Tesseract(String fileString) throws Exception {
String filePath = Start.class.getResource(fileString).getFile().toString();
// processImg(filePath);
File file = new File(filePath);
String recognizeText = new Tesseract().recognizeText(file);
System.out.println(recognizeText);
}
}
有可能你执行出错,无法在XX目录执行 tesseract…..
这个时候重启一下电脑就好了,原因是环境变量没有在idea中生效。
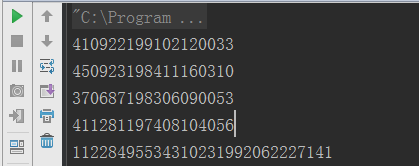
测试结果如下,目前还是比较满意的
后记
识别就先到这告一段落吧,下一篇日志我们继续如何使用H5识别身份证号码。
对识别率提高的其他思考
其实对号码的识别我也想过做一些处理,比如把身份证的背景纹路去掉,只留下身份证的数字。变成下面这样的
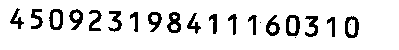 但是我发现,处理之后时候有的识别率反而降低了,没研究过tesseract-orc的原理,不知为何这样识别率反而降低。
但是我发现,处理之后时候有的识别率反而降低了,没研究过tesseract-orc的原理,不知为何这样识别率反而降低。
JAVA识别身份证号码,H5识别身份证号码,tesseract-ocr识别(二)
思路分析
H5拍照上传 —> 服务端截取身份证号码 —–> 识别号码 —–>返回信息
这几步,关键点在于 截取身份证号码这个步骤。我们期望的是正好截取到身份证号码的位置。
 这位大哥,罪过罪过,暂且借你图片一用,如侵犯了权益,请联系我,立马删除。
这位大哥,罪过罪过,暂且借你图片一用,如侵犯了权益,请联系我,立马删除。
最优方案 我觉得最好的办法是,直接在照相的界面出现一个红色的框框,让用户自己去对准身份证号码,可惜H5调用摄像头只能使用系统的界面,这个功能必须APP来做。没办法最优方案只好抛弃。 歪招 由于H5的限制,我想了一个歪招,用户上传完照片之后,看见图片才给他显示一个红框,如果识别错误,用户再次照相的时候自己去校准。 这个体验肯定非常不好,目前未使用APP的情况下,我们暂且这样吧。
处理图片 在截取身份证位置的时候,每个摄像头像素不一样怎么办呢?当然可以使用百分比截取。 而我使用的是对图片进行缩放,据我观察,大概缩放到 900x540,当然这会有一点变形。 具体值大家自行把握。 然后截取身份证号码的位置。具体值大家可以自行把握。
ImgCutUtil.zoomImage(src, src, 900, 540);
ImgCutUtil.cutImage(src, temp + filname, 290, 400, 600, 140);
return TesseractUtil.recognizeText(new File(temp + filname));
找到前端,把界面做出来,你看见的红色框框是一个div,是前端用CSS画出来的,当然你也可以在后台处理图片的时候,把你截取的那一部分加上红色框。展示界面如下。
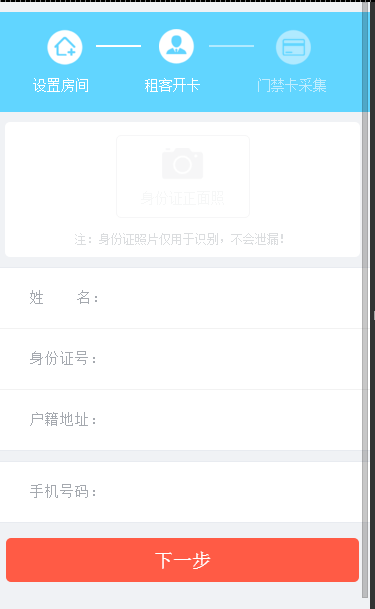
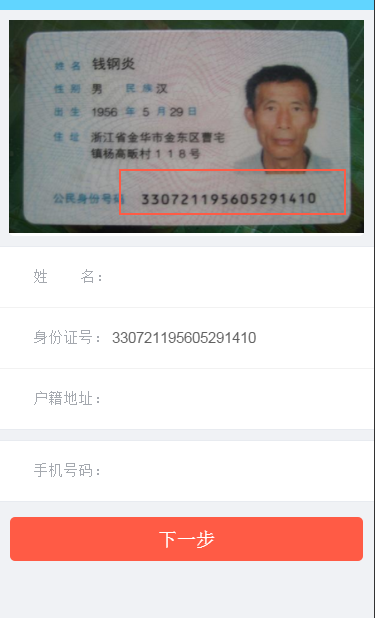
测试结果
使用Iphone5s、Iphone6、Iphone6s测试,识别效果良好错误率很少。 使用魅族测试,识别率低。照片模糊偏黄(是不是不对图片进行缩放会好些?大家可以测试一下) 测试结果证明一个道理,这个东西识别率要提高,必须要结合APP做!!!
后记
依照同样的思路,安装上中文语言包,然后对tesseract进行训练,是不是可以把所有的信息都是别呢?如果你做出来了请告诉我!!嘿嘿嘿。

本文由 创作,采用 知识共享署名4.0 国际许可协议进行许可。本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名。最后编辑时间为: 2020/11/13 07:18