如何设计一个高性能短链接服务
为什么要使用短链
来看下CSDN给我发的营销短信,详情点击超链接
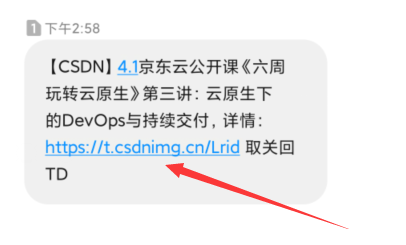 当你点击后 访问的网址是 https://edu.csdn.net/huiyiCourse/detail/1195?project_id=1195&utm_source=DW.我们打开F12控制台看一下
当你点击后 访问的网址是 https://edu.csdn.net/huiyiCourse/detail/1195?project_id=1195&utm_source=DW.我们打开F12控制台看一下
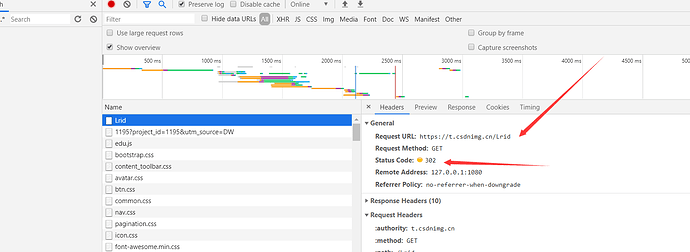
不难发现 访问短链接之后 进行了重定向。那么问题来了 为啥要用短链表示,直接用长链不行吗 反正都能访问到,其实不然,短链接的好处实在是长连接望尘莫及的。 举几个很现实的例子:
- 短信服务有长度限制,如果你用长链,光链接就占用了很多内容,而且超出的文本 将会按照2条短信费用收费,这就很划不来了,而且长链也很不美观,你懂的
- 我们经常需要把链接转换为二维码,如果链接过长,转换出来的二维码会很密集难识别,而短链接转换出来的二维码就很简洁易识别,短链接的好处简直不要太爽。
那么怎样才能生成短链呢,仔细观察上例中的短链,显然它是由固定短链域名 t.csdnimg.cn + 长链映射成的一串字母组成,那么长链怎么才能映射成一串字母呢。
大家可能会想到哈希函数,没错就是他了,可是哈希函数这么多,用哪个呢? 这里推荐Guava包下的MurmurHash 算法, MurmurHash 是一种 非加密型 哈希函数,适用于一般的哈希检索操作。与其它流行的哈希函数相比,对于规律性较强的 key,MurmurHash 的随机分布特征表现更良好。
MurmurHash 提供了两种长度的哈希值,32 bit,128 bit,为了让网址尽可通地短,我们选择 32 bit 的哈希值,32 bit 能表示的最大值近 43 亿,对于非大型公司的业务而言绰绰有余。
对上文提到的CSDN长链做 MurmurHash 计算 得到的哈希值为1692630244,于是我们现在得到的短链为 固定短链域名+哈希值 = http://t.csdnimg.cn/1692630244 3
我们发现 链接依旧有点长而且结尾全是数字 好像和人家的数字字母混合的不一样啊。没错 1692630244是十进制的 我们还需要对它进行进制的转换,那转换为多少进制合适呢?答案是62。
我们将1692630244转换为62进制 得到的值为1Qy6rO 那么现在的网址就是 http://t.csdnimg.cn/1Qy6rO了,既然访问访问短链能跳转到长链,那么两者之间的映射关系一定是要保存起来,可以用 Redis 或 Mysql 等,这里我们选择用 Mysql 来存储。
看到这里,好像问题已经得到了解决,其实不然,我们调用的是哈希函数,既然是哈希函数,不可避免地会产生哈希冲突(尽管概率很低),该怎么解决呢。 于是我们有了以下设计思路。
- 将长链(lurl)经过 MurmurHash 后得到十进制的数字短链。
- 将10进制的数字短链转换为62的进制的短链
- 再根据短链去数据库表中查找看是否存在相关记录,如果不存在,将长链与短链对应关系插入数据库中,存储。
- 如果存在,说明已经有相关记录了,此时在长串上拼接一个自定义好的字段,比如「ALREADY」,然后再对接接的字段串「url + ALREADY」做第一步操作,如果最后还是重复呢,再拼一个字段串啊,这样重复的问题就解决了。
但是以上步骤显然是要优化的,插入一条记录经过了两次 sql 执行(查询是否存在和插入),如果在高并发下,显然会承受不住。
聪明的你可能又想到了解决方法,我可以给短链接加上唯一索引啊,然后根据插入的返回值,判断是否插入成功,是的,这是一种解决办法,但是在数据量很大的情况下,冲突的概率会增大,此时布隆过滤器就登场了。什么,布隆过滤器?一部分读者可能想到了那个来自弗雷尔卓德举着高高的盾牌的男人,其实不是。他们只是重名而已。。。
布隆过滤器是一种非常省内存的数据结构,长度为 10 亿的布隆过滤器,只需要 125 M 的内存空间 所以我们有了新的思路。
- 将长链(lurl)经过 MurmurHash 后得到十进制的数字短链。
- 查询布隆过滤器中是否存在该数字短链,如果存在,则拼接字符串重新生成数字短链
- 将10进制的数字短链转换为62的进制的短链
- 将长链与短链对应关系插入数据库中,存储。
说了这么多,相信你已经明白了大致的步骤,光说不练假把式,下面上代码:
首先导入Guava的jar包:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.2-jre</version>
</dependency>
@Controller
public class controller {
@Autowired
private UrlService urlService;
int size = 1000000;//预计要插入多少数据
double fpp = 0.001;//期望的误判率
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp);
@RequestMapping("/{short_url}")
public String url(@PathVariable("short_url")String short_url)
{
//根据短链查询对应的长链
String longurl = urlService.select(short_url);
//重定向到长链
String url="redirect:"+longurl;
return url;
}
@RequestMapping("bloom")
@ResponseBody
public String bloom(String longUrl)
{
//将长url转换为短url
String to62url=to62url(longUrl);
//插入数据库
urlService.insert(to62url, longUrl);
return to62url;
}
//将长url转换为短url
public String to62url(String longUrl)
{
//MurmurHash算法
HashFunction function= Hashing.murmur3_32();
HashCode hashCode = function.hashString(longUrl, Charset.forName("utf-8"));
//i为长url的murmur值
int i = Math.abs(hashCode.asInt());
//准备一个url在生成的murmur值重复时拼接字符串用
String newurl=longUrl;
//bo如果为true说明布隆过滤器中已存在
boolean bo=bloomFilter.mightContain(i);
while(bo)
{
newurl+="ALREADY";
hashCode = function.hashString(newurl, Charset.forName("utf-8"));
//使用拼接过字符串的url重新生成murmur值
i = Math.abs(hashCode.asInt());
bo=bloomFilter.mightContain(i);
}
//将murmur值放入布隆过滤器
bloomFilter.put(i);
//转成62进制位数更短
String to62url = encode(i);
return to62url;
}
//将目标转换为62进制 位数更短
public String encode(long num) {
String chars = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
int scale = 62;
StringBuilder sb = new StringBuilder();
int remainder = 0;
while (num > scale - 1) {
remainder = Long.valueOf(num % scale).intValue();
sb.append(chars.charAt(remainder));
num = num / scale;
}
sb.append(chars.charAt(Long.valueOf(num).intValue()));
return sb.reverse().toString();
}
由于布隆过滤器数据是在内存中,那么我们的项目暂停重启后 布隆过滤器的数据会消失,所以我们需要进行数据的持久化和还原
@RequestMapping("persist")
@ResponseBody
public String persist()
{
File f= new File("f:" + File.separator + "bloom");
OutputStream out = null;
try {
out = new FileOutputStream(f);
bloomFilter.writeTo(out);
} catch (IOException e) {
throw new RuntimeException(e);
}
return "持久化布隆过滤器数据成功";
}
//将本地的数据还原到布隆过滤器
@RequestMapping("resume")
@ResponseBody
public String resume()
{
File f= new File("f:" + File.separator + "bloom") ;
InputStream in = null;
try {
in = new FileInputStream(f);
bloomFilter = BloomFilter.readFrom(in,Funnels.integerFunnel());
} catch (IOException e) {
throw new RuntimeException(e);
}
return "恢复布隆过滤器数据成功";
}
效果动图(本地测试)
本文由 创作,采用 知识共享署名4.0 国际许可协议进行许可。本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名。最后编辑时间为: 2021/07/15 01:47